Motivation
To get my hands dirty in the field of AI research I thought of first studying the complete lifecycle of how these frontier research lab companies go from just huge amounts of data to a model that has PhD Level intelligence.
To understand this it made sense to check out open-source recipes and blog posts like that by Hugging Face or by open research labs like AI2.
Searching through these I came across a very cool and simple to understand lifecycle blog of how the AI2 team trained their OLMo 3 model: AI2 OLMo 3 blog.
After reading this I had a clear picture in my head, especially Saurabh Shah’s (@saurabh_shah2) Substack, “Training OLMo 3 to Think and Code”, of how these models are trained from raw text data taken from the entire internet, trillions of tokens, to then generating tokens, basically predicting the next token themselves.
After reading this I even tweeted:
https://x.com/arora_mrinaal/status/2024835177307140212

Through this I was able to get a rough idea how these AI labs go about things or like what’s the major steps involved when training an AI model, the different phases of it, pre-training, mid-training, and post-training.
The most interesting thing to me was the thinking SFT part of it, when we take a base pre-trained model and teach it to emit reasoning traces, those <think> tags that you see the model do.
Reasoning Traces And Why Labs Hide Them
When you use closed source frontier models like ChatGPT 5.4, Claude Opus 4.6, or even Gemini 3.1 Pro, all of these are reasoning models, meaning these models think before actually responding to your query.
These frontier labs hide the thinking and reasoning traces of these models and instead what we see are Thinking Summaries, which I guess might be generated by a smaller model or maybe the bigger model itself is hiding it, so that others can’t actually take these traces and distill from these models and create smaller and cheaper models.
Anthropic has talked about this here: https://x.com/AnthropicAI/status/2025997928242811253

I also tried to make sense of this distillation topic for me so that I could understand this term and the topic itself: https://x.com/arora_mrinaal/status/2026314927200182588
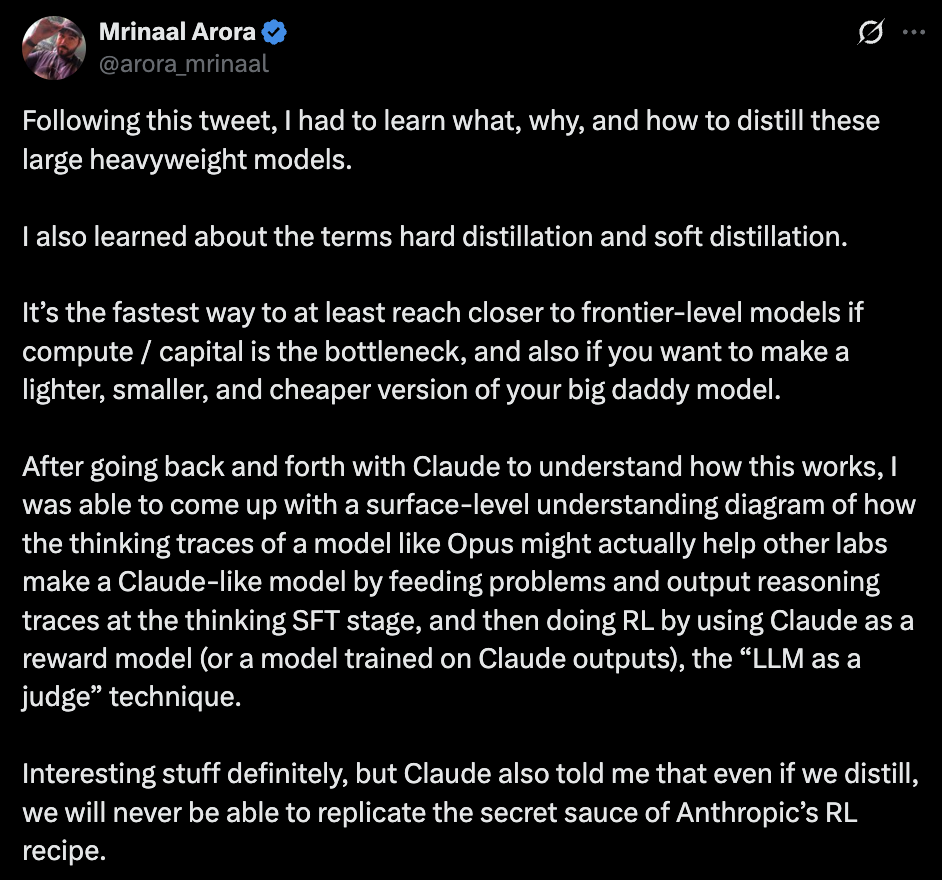
So I decided to take a small base pre-trained model and teach it to emit thinking traces, meaning to reason before answering.
Model Choice
So I picked Nanbeige4-3B-Base by Nanbeige LLM Lab (@nanbeige).
It’s a small but strong base model pre-trained on 23T tokens. Its training data also included knowledge-dense and reasoning-intensive synthetic data such as Q&A pairs, textbooks, and long chains of thought.
Because of that pre-training mix, I assumed the model would already have at least some familiarity with this style of reasoning and with <think> tags.
Approach
After talking with Claude for a while, I used it to figure out how to approach this setup.
I came to know how to go about this SFT, or cold start SFT, or thinking SFT, whatever you call it, using the LoRA technique.
LoRA is really interesting because instead of updating every weight in the model we train an adaptive layer on top of it, so the model learns to imitate this reasoning and thinking behavior, which is really compute-friendly.
Context tweet: https://x.com/arora_mrinaal/status/2028402435648315576
For my trial run I picked a 2.1k row small dataset that had reasoning traces from Opus 4.6.
For my second actual run I picked 12k rows out of the large 25k row dataset.
I trained the model on the Assistant side of output using this format. From the datasets I got the problem, thinking, and solution triplets.
User: {problem}
Assistant: <think>
{thinking}
</think>
{solution}
Training Runs On Modal
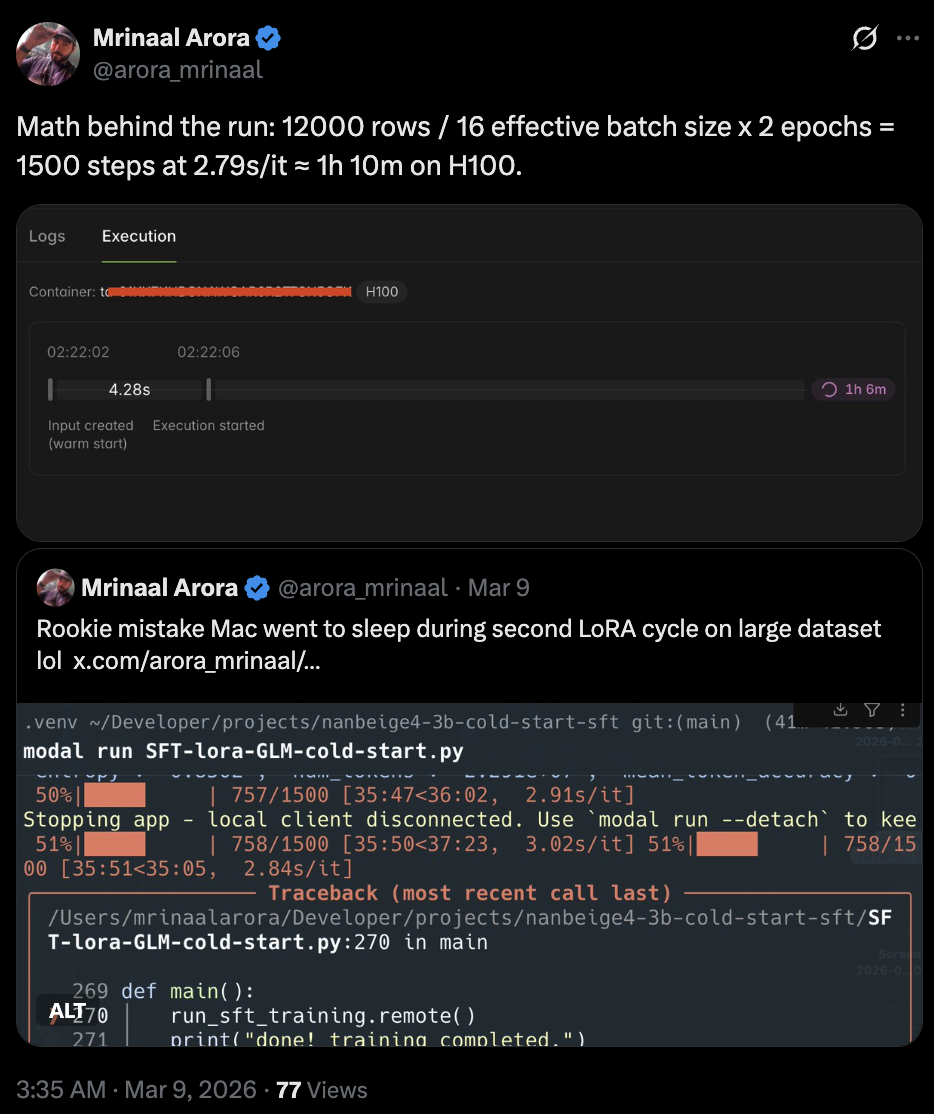
I ran the job on Modal’s GPU cloud infrastructure using an NVIDIA H100 GPU. The small dataset test run took about 10 minutes, while the bigger run with 12k rows took about 1 hour and 13 minutes.
The math behind the run was:
- 12000 rows
- 16 effective batch size
- 2 epochs
- 1500 steps
- 2.79 seconds per iteration
- about 1h 10m on H100
Related tweet: https://x.com/arora_mrinaal/status/2030766843158503885
Source Model Difference, GLM Versus Opus
My v1 adapter was trained on Claude Opus 4.6 reasoning traces, which is very different in output quality compared with GLM-5, even though both were frontier models at the time.
Opus 4.6 tends to produce very structured, verbose reasoning.
I might be wrong as a beginner here, but in the tests I ran, inference with the base model plus the adapter trained on Opus 4.6 traces produced much better outputs, even though that dataset was small, than the run trained on GLM-5 data with 12,000 rows for 2 epochs.
Learning Curves And The Mistake That Hurt
For the second training run, the bigger one, I asked Claude how to see those graphs, the learning curves that ML researchers go bonkers for, with loss and steps on the axes. I asked it to write a script for the loss curve and a couple of other graphs.
As of now, I will be honest, theoretically I could only grasp the training loss curve and a bit of the token length histogram. The token length histogram was the alarming one in my case because 78.8% of my examples were being truncated at 2048 tokens. For most of my examples, this means the model was never shown the closing tag or the {solution} at all during training.
The model was learning to reason but never learned how to close its thinking and produce a final answer, because that part was always cut off. And this actually was the reason the outputs of the adapter weights and base model, when I ran inference, the model was unable to end its response.
This particular graph made me realize that in this field, one small error can waste a lot of compute. And for a GPU-poor person like me who survives on credit-based cloud infrastructure, this is not sustainable for running that many projects. I should start jobs in the cloud only when I am 100% sure that the run will succeed, but then again, this field is full of experiments.
The Scale Realization
After this whole process, when I saw the outputs with adapter weights with just a small dataset, I realized how big labs with no compute constraint would do this stuff.
At that scale they can full-parameter fine-tune and update every single weight in the model, such that this type of thinking behavior becomes baked into the model, rather than in my case where the model is trying to imitate it through LoRA adapters.
Diagram And Where This Fits In The Bigger Pipeline
Here is a diagram I drew to visualize the process of making a dense 32B thinking model.
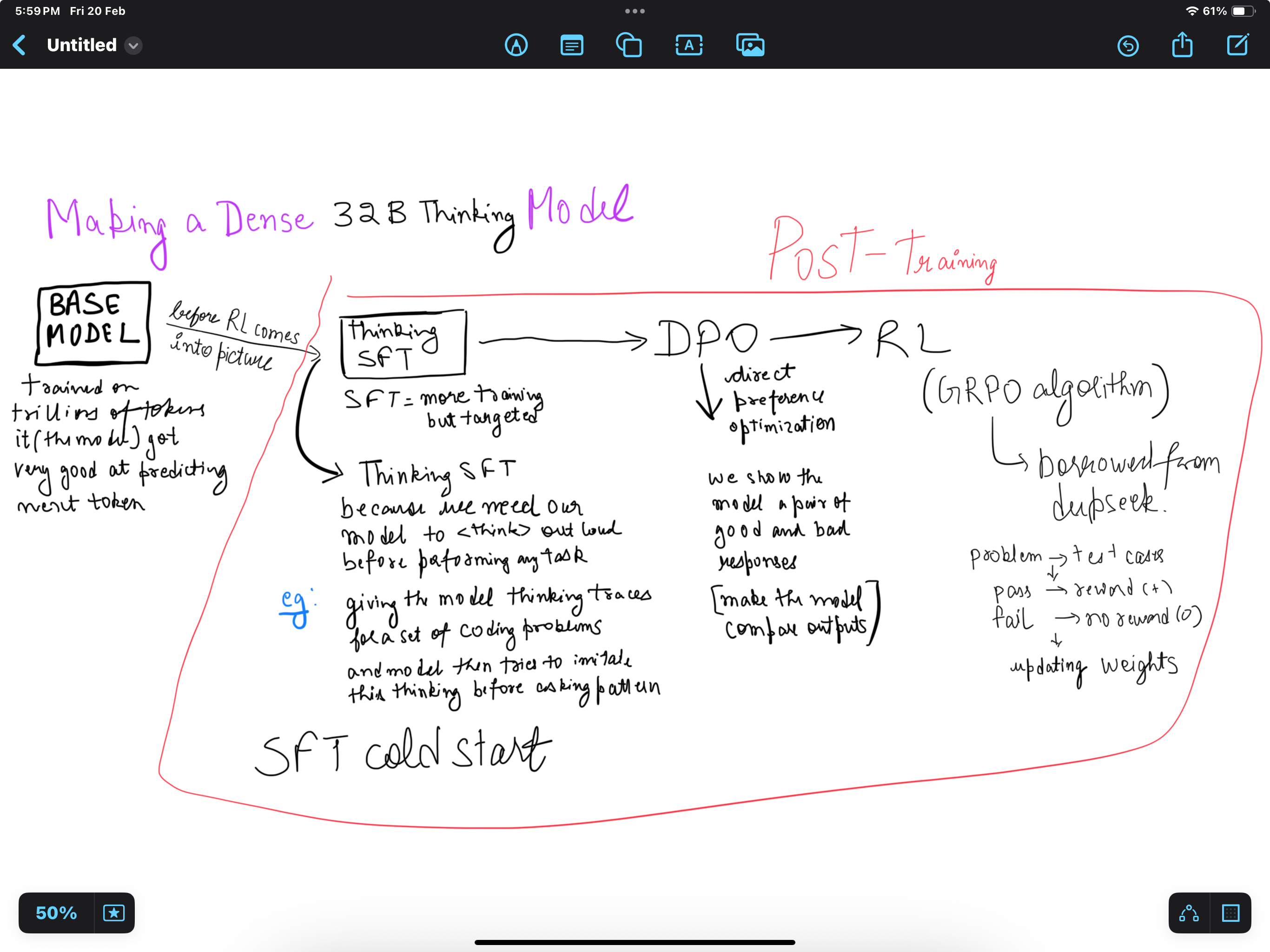
It starts with the base model, which is trained on trillions of tokens and becomes good at predicting the next token.
Before RL comes into the picture, there is Thinking SFT, which is a more targeted form of supervised fine-tuning. For example, we can give the model reasoning traces for a set of coding problems, and the model then tries to imitate this think-before-answer pattern. This is the cold-start SFT stage.
Then, in post-training, there is DPO, or Direct Preference Optimization. Here we show the model pairs of good and bad responses and train it to prefer the better outputs.
After that comes RL, often using algorithms like GRPO borrowed from DeepSeek. For example, if a solution passes the test cases, the model gets a positive reward; if it fails, it gets no reward, and the weights are updated accordingly.
Next
As of my current reading in general deep learning stuff I am finding the concept of RL quite interesting.
So I might go study deep and do my next experiment something related to RL.
Links
Experiments
Reading And Motivation
Datasets
Motivation
To get my hands dirty in the field of AI research I thought of first studying the complete lifecycle of how these frontier research lab companies go from just huge amounts of data to a model that has PhD Level intelligence.
To understand this it made sense to check out open-source recipes and blog posts like that by Hugging Face or by open research labs like AI2.
Searching through these I came across a very cool and simple to understand lifecycle blog of how the AI2 team trained their OLMo 3 model: AI2 OLMo 3 blog.
After reading this I had a clear picture in my head, especially Saurabh Shah’s (@saurabh_shah2) Substack, “Training OLMo 3 to Think and Code”, of how these models are trained from raw text data taken from the entire internet, trillions of tokens, to then generating tokens, basically predicting the next token themselves.
After reading this I even tweeted: https://x.com/arora_mrinaal/status/2024835177307140212
Through this I was able to get a rough idea how these AI labs go about things or like what’s the major steps involved when training an AI model, the different phases of it, pre-training, mid-training, and post-training.
The most interesting thing to me was the thinking SFT part of it, when we take a base pre-trained model and teach it to emit reasoning traces, those
<think>tags that you see the model do.Reasoning Traces And Why Labs Hide Them
When you use closed source frontier models like ChatGPT 5.4, Claude Opus 4.6, or even Gemini 3.1 Pro, all of these are reasoning models, meaning these models think before actually responding to your query.
These frontier labs hide the thinking and reasoning traces of these models and instead what we see are Thinking Summaries, which I guess might be generated by a smaller model or maybe the bigger model itself is hiding it, so that others can’t actually take these traces and distill from these models and create smaller and cheaper models.
Anthropic has talked about this here: https://x.com/AnthropicAI/status/2025997928242811253
I also tried to make sense of this distillation topic for me so that I could understand this term and the topic itself: https://x.com/arora_mrinaal/status/2026314927200182588
Model Choice
So I picked Nanbeige4-3B-Base by Nanbeige LLM Lab (@nanbeige).
It’s a small but strong base model pre-trained on 23T tokens. Its training data also included knowledge-dense and reasoning-intensive synthetic data such as Q&A pairs, textbooks, and long chains of thought.
Because of that pre-training mix, I assumed the model would already have at least some familiarity with this style of reasoning and with
<think>tags.Approach
After talking with Claude for a while, I used it to figure out how to approach this setup.
I came to know how to go about this SFT, or cold start SFT, or thinking SFT, whatever you call it, using the LoRA technique.
LoRA is really interesting because instead of updating every weight in the model we train an adaptive layer on top of it, so the model learns to imitate this reasoning and thinking behavior, which is really compute-friendly.
Context tweet: https://x.com/arora_mrinaal/status/2028402435648315576
Datasets And Training Format
For my trial run I picked a 2.1k row small dataset that had reasoning traces from Opus 4.6.
For my second actual run I picked 12k rows out of the large 25k row dataset.
I trained the model on the Assistant side of output using this format. From the datasets I got the problem, thinking, and solution triplets.
Training Runs On Modal
I ran the job on Modal’s GPU cloud infrastructure using an NVIDIA H100 GPU. The small dataset test run took about 10 minutes, while the bigger run with 12k rows took about 1 hour and 13 minutes.
The math behind the run was:
Related tweet: https://x.com/arora_mrinaal/status/2030766843158503885
Source Model Difference, GLM Versus Opus
My v1 adapter was trained on Claude Opus 4.6 reasoning traces, which is very different in output quality compared with GLM-5, even though both were frontier models at the time.
Opus 4.6 tends to produce very structured, verbose reasoning.
I might be wrong as a beginner here, but in the tests I ran, inference with the base model plus the adapter trained on Opus 4.6 traces produced much better outputs, even though that dataset was small, than the run trained on GLM-5 data with 12,000 rows for 2 epochs.
Learning Curves And The Mistake That Hurt
For the second training run, the bigger one, I asked Claude how to see those graphs, the learning curves that ML researchers go bonkers for, with loss and steps on the axes. I asked it to write a script for the loss curve and a couple of other graphs.
As of now, I will be honest, theoretically I could only grasp the training loss curve and a bit of the token length histogram. The token length histogram was the alarming one in my case because 78.8% of my examples were being truncated at 2048 tokens. For most of my examples, this means the model was never shown the closing tag or the
{solution}at all during training.The model was learning to reason but never learned how to close its thinking and produce a final answer, because that part was always cut off. And this actually was the reason the outputs of the adapter weights and base model, when I ran inference, the model was unable to end its response.
This particular graph made me realize that in this field, one small error can waste a lot of compute. And for a GPU-poor person like me who survives on credit-based cloud infrastructure, this is not sustainable for running that many projects. I should start jobs in the cloud only when I am 100% sure that the run will succeed, but then again, this field is full of experiments.
The Scale Realization
After this whole process, when I saw the outputs with adapter weights with just a small dataset, I realized how big labs with no compute constraint would do this stuff.
At that scale they can full-parameter fine-tune and update every single weight in the model, such that this type of thinking behavior becomes baked into the model, rather than in my case where the model is trying to imitate it through LoRA adapters.
Diagram And Where This Fits In The Bigger Pipeline
Here is a diagram I drew to visualize the process of making a dense 32B thinking model.
It starts with the base model, which is trained on trillions of tokens and becomes good at predicting the next token.
Before RL comes into the picture, there is Thinking SFT, which is a more targeted form of supervised fine-tuning. For example, we can give the model reasoning traces for a set of coding problems, and the model then tries to imitate this think-before-answer pattern. This is the cold-start SFT stage.
Then, in post-training, there is DPO, or Direct Preference Optimization. Here we show the model pairs of good and bad responses and train it to prefer the better outputs.
After that comes RL, often using algorithms like GRPO borrowed from DeepSeek. For example, if a solution passes the test cases, the model gets a positive reward; if it fails, it gets no reward, and the weights are updated accordingly.
Next
As of my current reading in general deep learning stuff I am finding the concept of RL quite interesting.
So I might go study deep and do my next experiment something related to RL.
Links
Experiments
Reading And Motivation
Datasets