Why This One Felt Different
The hidden reason I ended up here is honestly the last two RL blogs.
In my first RL experiment, I learned what it feels like when a reward function quietly stops being useful. In my second RL experiment, I learned that even if the infra is cleaner, the task can still be too easy or too hard for GRPO to have anything meaningful to do.
So by the time I started this one, I was not just randomly trying another RL run. I was specifically looking for my first successful RL training run, meaning a run where the reward actually trends up, the system stays healthy, and I can explain to myself why it improved. That is what this turned into. I trained Qwen3-1.7B to play Wordle using Hugging Face TRL's GRPOTrainer, connected to a live TextArena Wordle environment running on a Hugging Face Space.
After a couple of weeks of learning RL from scratch, this was the first time I got a reward curve that actually went up because of something I trained and understood end to end.
How I Got Pulled Into OpenEnv
Part of the reason this happened now is that I am participating in the Meta x PyTorch x Hugging Face hackathon by Scaler School of Technology. The hackathon goal is to build an RL environment for agents and LLMs using the new OpenEnv framework.
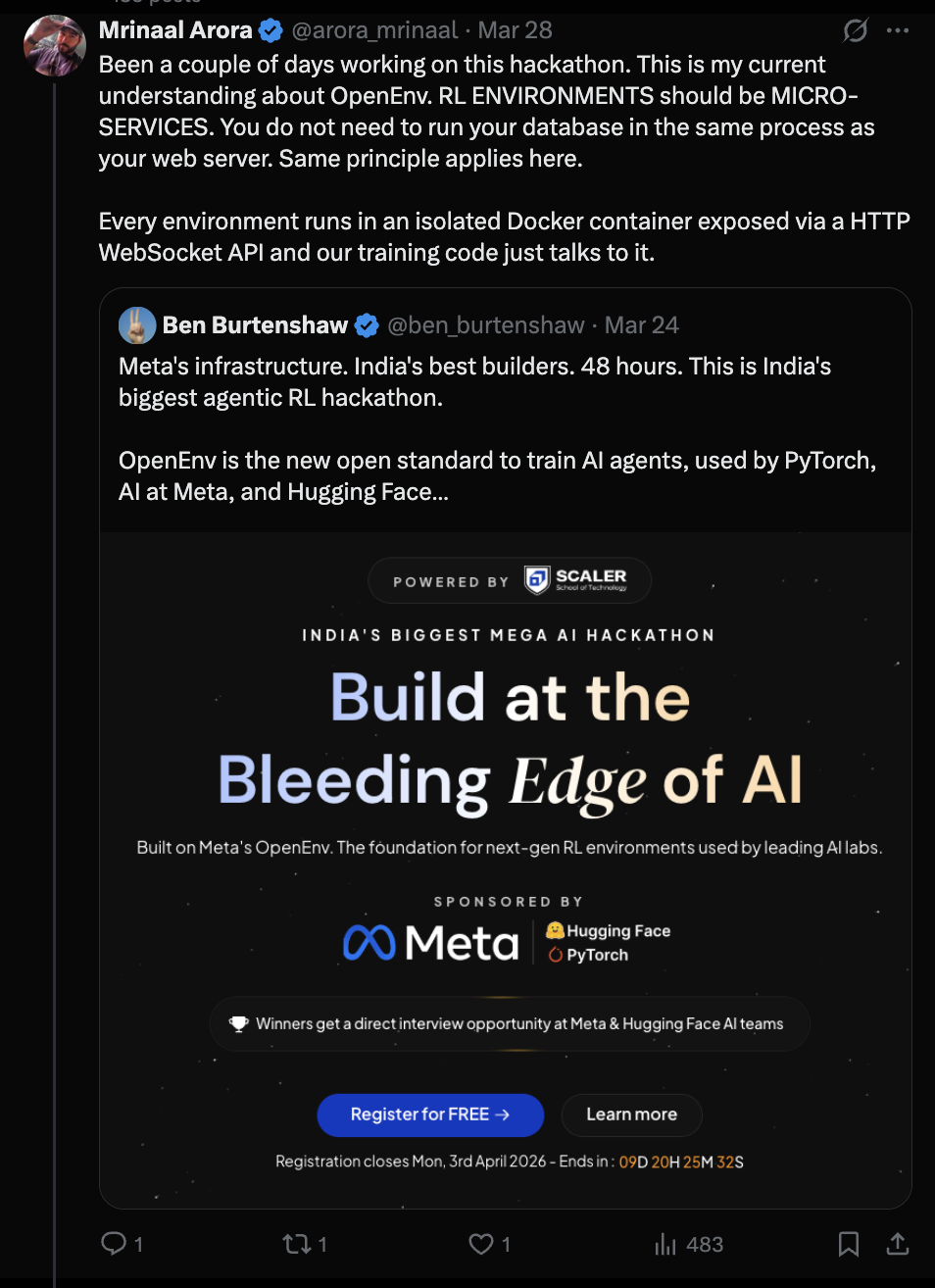
That was the moment I stopped thinking only about "how do I run GRPO?" and started thinking more about what an RL environment even is.
The core OpenEnv idea clicked for me in a very software engineering way. RL environments should be microservices. You do not need to run your database inside the same process as your web server. Same idea here. The environment can live in its own isolated Docker container, exposed through HTTP or WebSocket APIs, and the training code just talks to it.
I even drew out my mental model while trying to understand it.
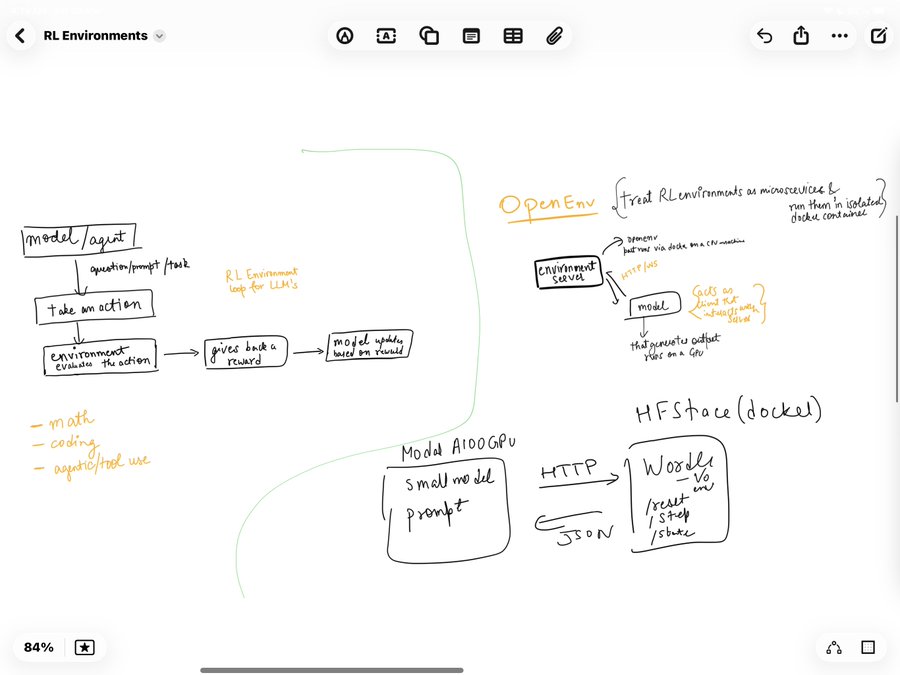
Once that clicked, the rest of the setup started making much more sense in my head. Modal would host the training job and the model. The environment would live separately as a service. The trainer would just send actions to it, receive observations and rewards back, and keep updating the model.
Why Wordle Became My Starter RL Environment
While going through the OpenEnv training tutorial, I came across the example that uses TRL to train a model to play Wordle through interaction and reinforcement. The moment I saw that, the idea felt too clean not to try.
Why not take a small model, connect it to a live TextArena Wordle environment, and let GRPO learn from the game loop itself?
To get started quickly, I duplicated the recommended hosted Hugging Face Space to my own account so I would have my own environment endpoint to hit during training. Before running actual RL, I first wanted to validate the whole pipe. I wrote a small script just to test the connection between my Modal container and the hosted Wordle environment.
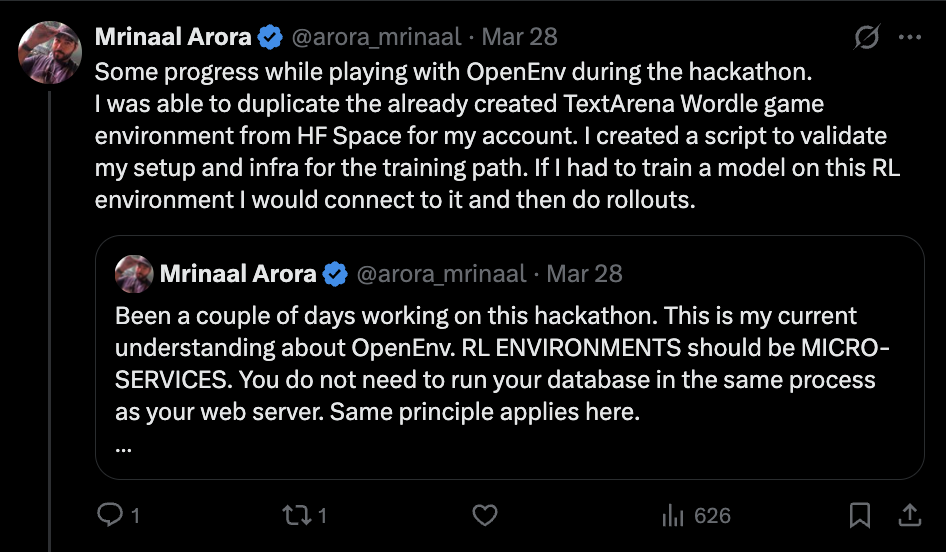
That validation step mattered a lot for me because after the previous two RL blogs, I did not want to confuse "the environment pipe is broken" with "the RL setup is weak." I wanted at least one experiment where the infrastructure path itself felt boring in a good way.
The Training Stack
The full stack I used was simple enough that it still feels a bit unreal to me:
- Modal A100 80GB for training compute
- TRL with
GRPOTrainer
vLLM colocate mode for fast generation during training- A live TextArena Wordle environment hosted on my duplicated Hugging Face Space
- A hosted metrics dashboard so I could watch the run live
For the model, I picked Qwen3-1.7B, exactly as mentioned in the tutorial.
One detail that also matters here: this was a full weights run, not LoRA. There was no peft_config in the GRPOTrainer call, which means all 1.7B parameters were being updated. So the weights coming out of this run were a real fine tune. I pushed those final weights here as wordle-grpo-Qwen3-1.7B on Hugging Face.
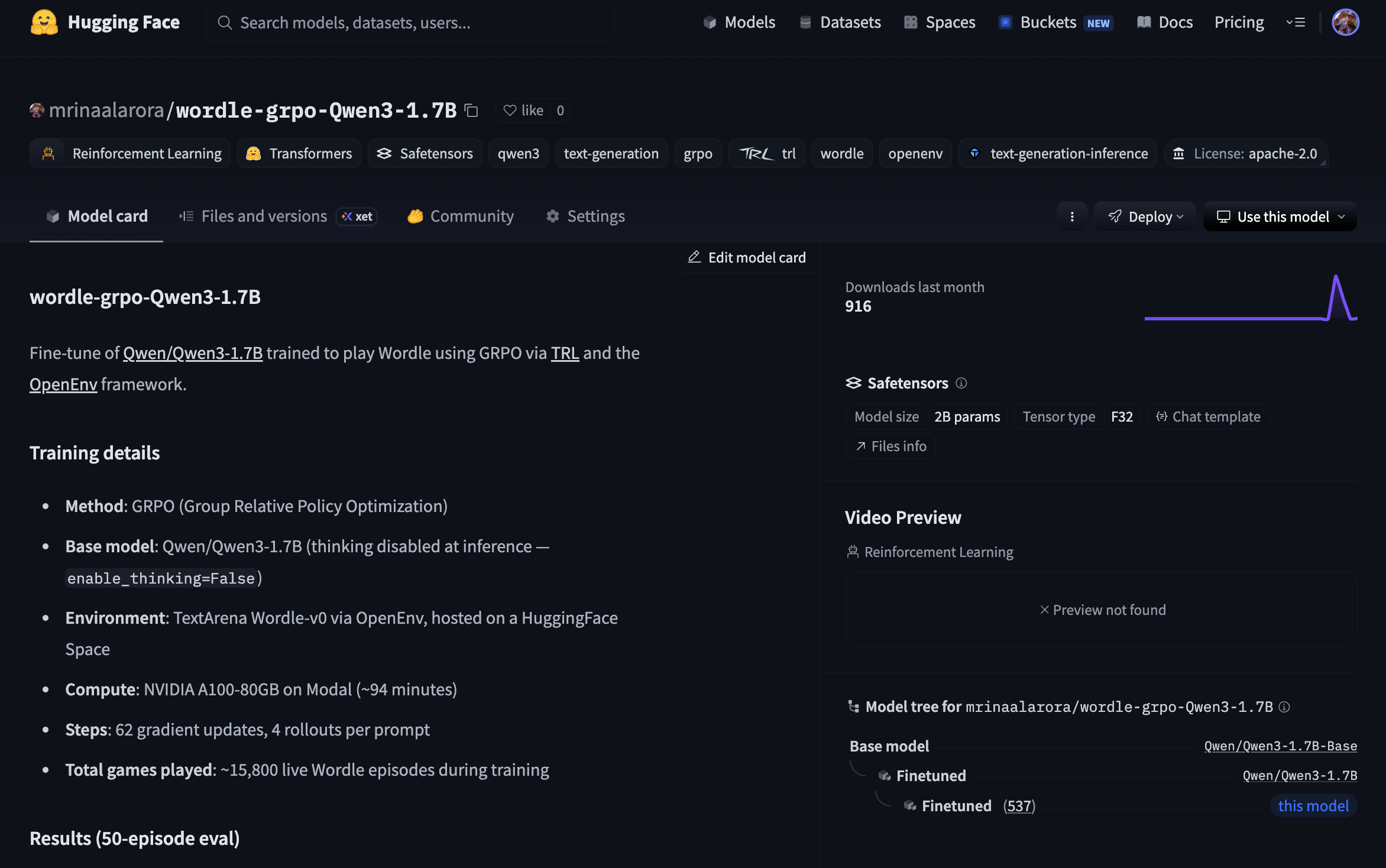
The Actual Run
The training job ran on Modal for about 1h 34m on an A100 80GB.
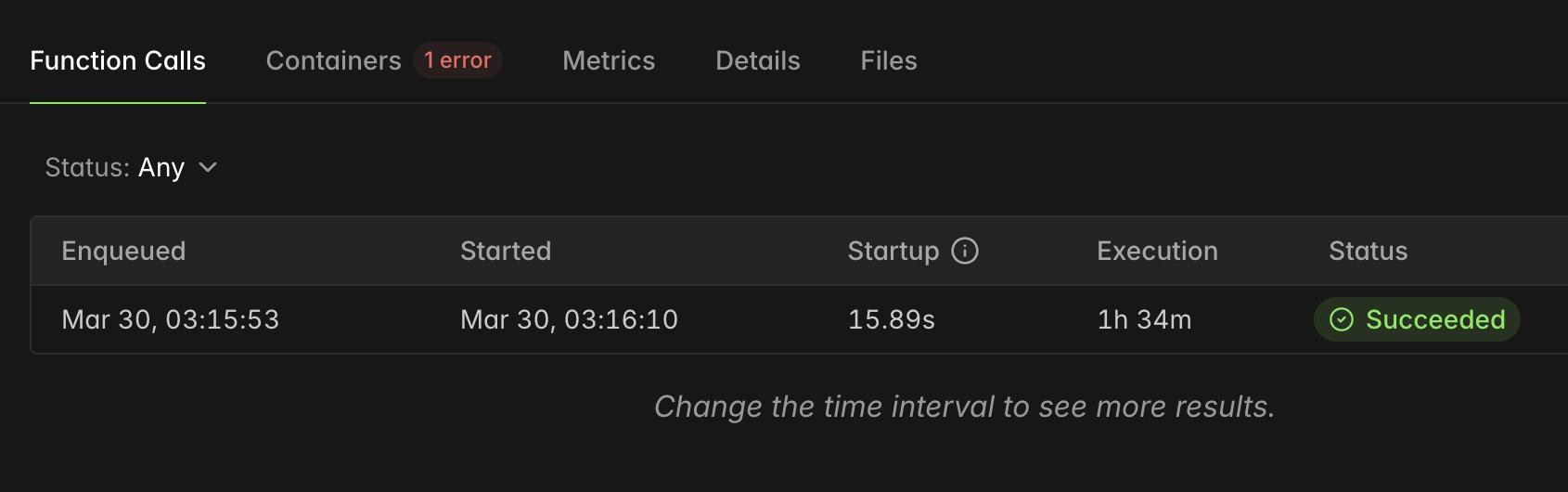
The shape of the run was:
62 gradient steps4 rollouts per prompt- about
15,800 live Wordle games played during training
That number is what made this whole thing feel especially cool to me. This was not offline RL with some static reward labels already sitting in a dataset. The model was interacting with a live environment, making guesses, getting feedback, and slowly adjusting itself inside that loop.
My First Reward Curve That Actually Went Up
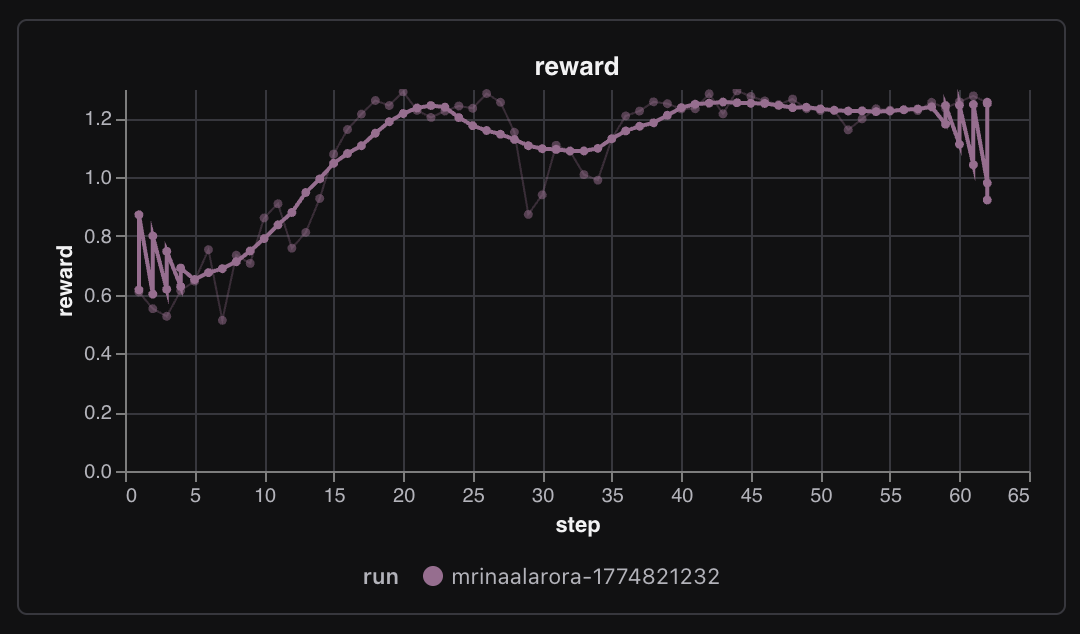
The main graph tells the story instantly.
If you want to look at the full live metrics view itself, the Trackio dashboard is here: qwen3-1.7b-grpo-62s-4r-2run.
train/reward went from about 0.61 to 1.28.
That is not some tiny wiggle where you have to convince yourself the run maybe worked. The reward almost doubled. After the two RL experiments before this one, just seeing that curve move in the right direction felt kind of surreal.
But the better part is that I can also explain why it went up.
The biggest driver was the repetition reward.
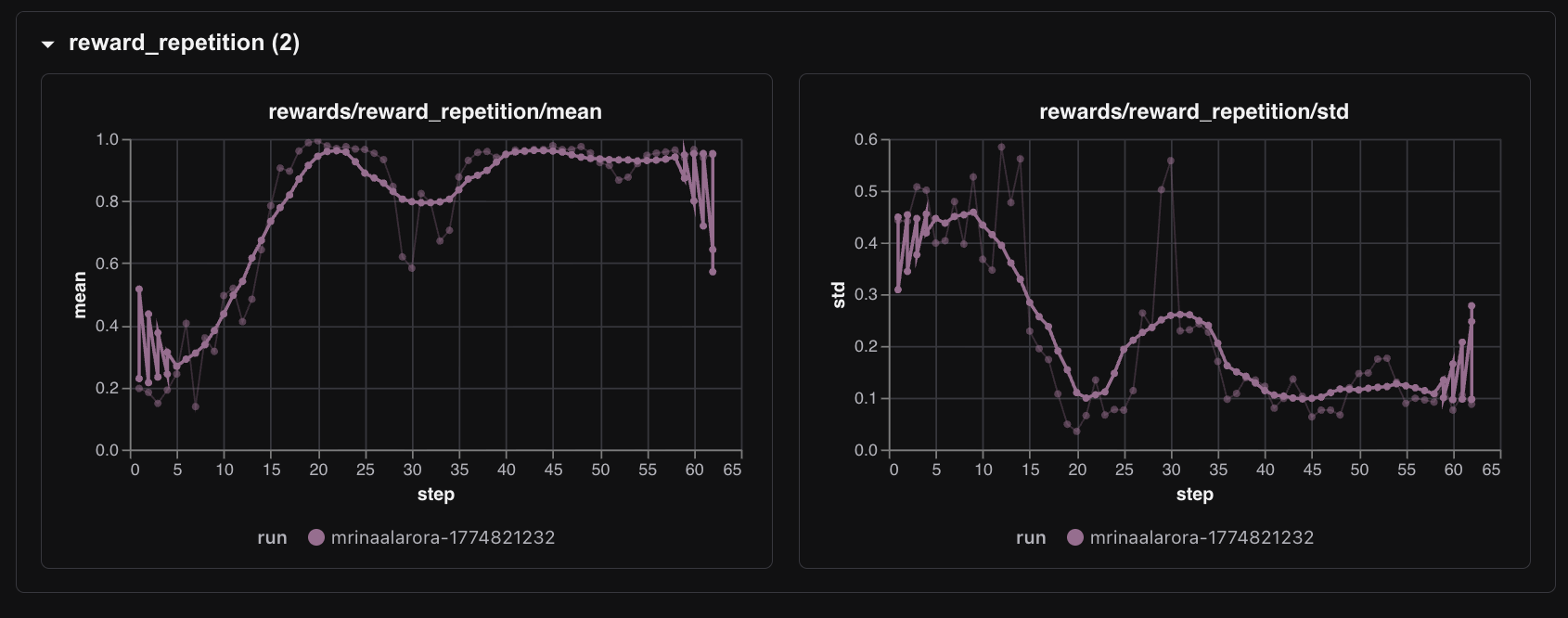
rewards/reward_repetition/mean moved from around 0.20 to around 0.95.
That is real behavioral learning. The model was learning one of the first core Wordle rules: stop wasting turns by repeating guesses. This is also what made the run feel qualitatively different from my earlier RL attempts. The reward was not just some fragile parse of the last token. It had shaped components tied to actual gameplay behavior, and the model found the most learnable one first.
The correctness reward stayed much smaller, but it did start appearing.
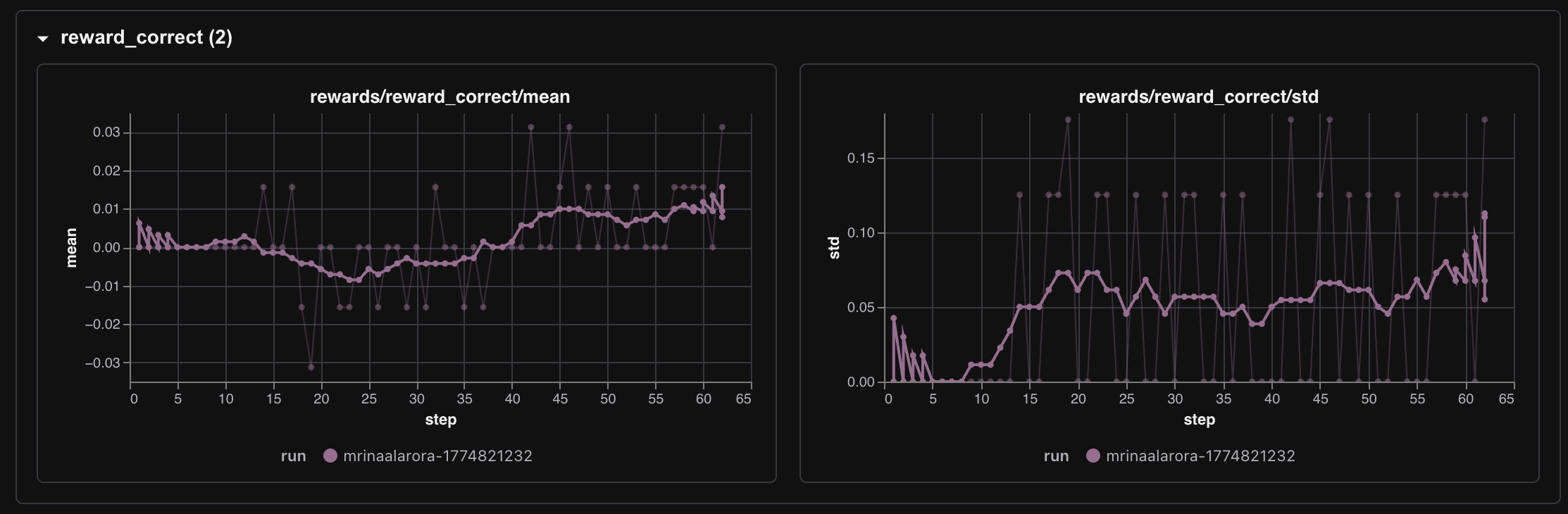
rewards/reward_correct/mean started around 0.0 and later reached roughly 0.015 to 0.031. So no, the model did not suddenly become a monster Wordle agent. But it did start solving games occasionally, and the first real signs of that showed up around step 14.
The greens and yellows rewards told a softer story.
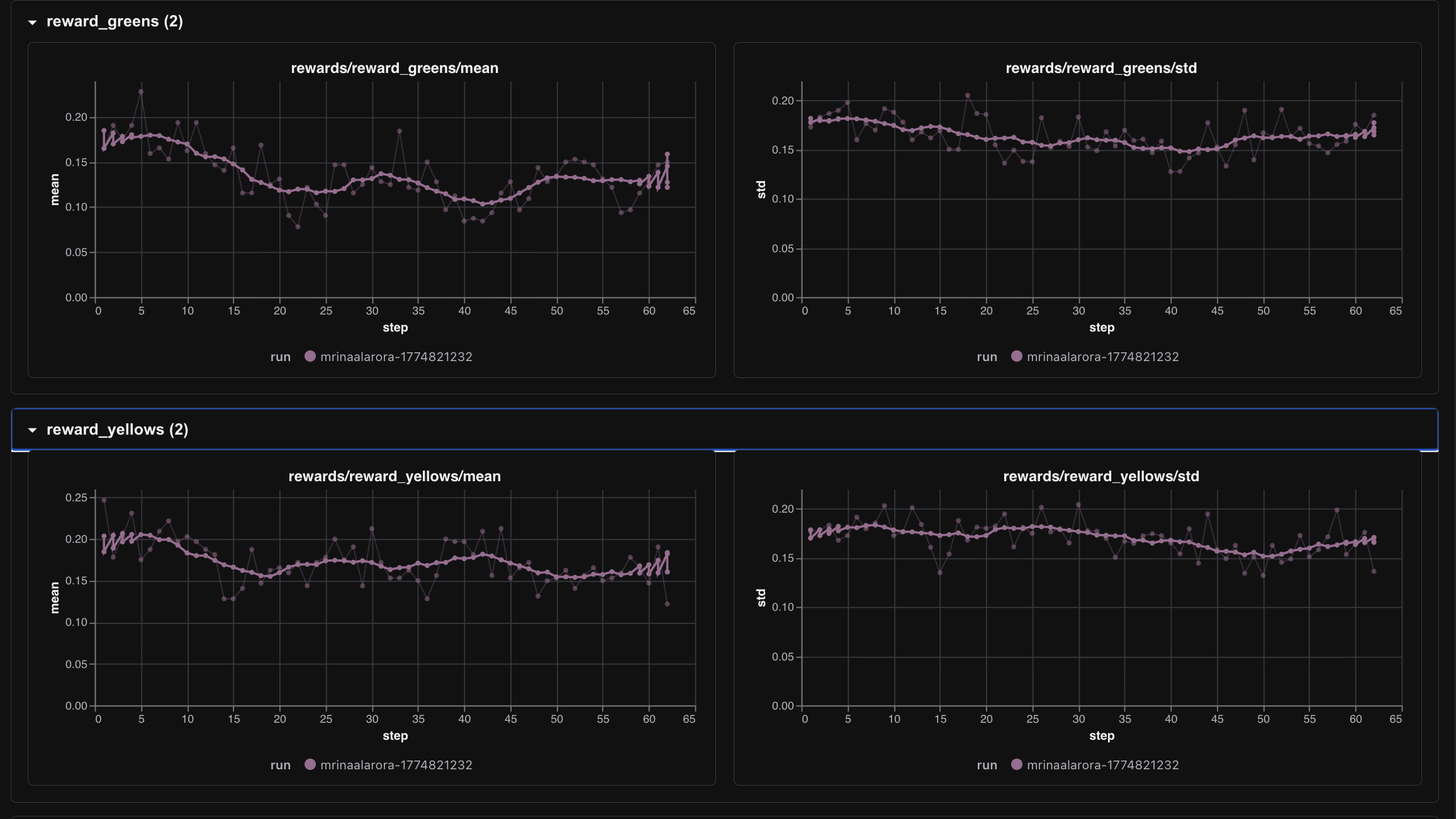
Those metrics were not the dramatic part of the run. They moved, but not in the same obvious way as repetition reward. To me that makes sense. Not repeating guesses is a much easier behavioral principle to learn early than actually solving Wordle consistently. The model first learned how to avoid a dumb mistake. Only after that did it start showing rare signs of genuine solving.
The training loss also looked mechanically healthy enough throughout the run.
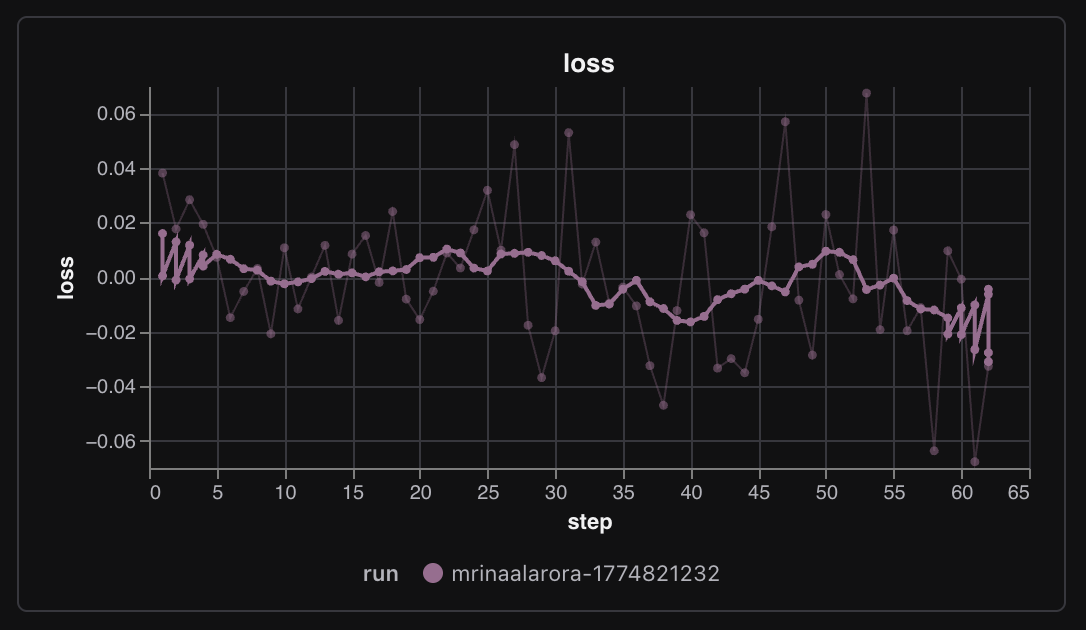
It was noisy, yes, but not broken. And the other logs matched that feeling too. Entropy went from about 0.13 to 0.47, which tells me the model got more exploratory in its guesses. sampling/IS_ratio stayed around 1.0 all 62 steps, which is exactly the kind of boring number I wanted to see. Boring is good when you are trying to trust the mechanics.
Did It Actually Play Better
I did not want to stop at the training dashboard, so I ran evals separately using vLLM on Modal as well.
The quick 10 episode eval already showed the direction.
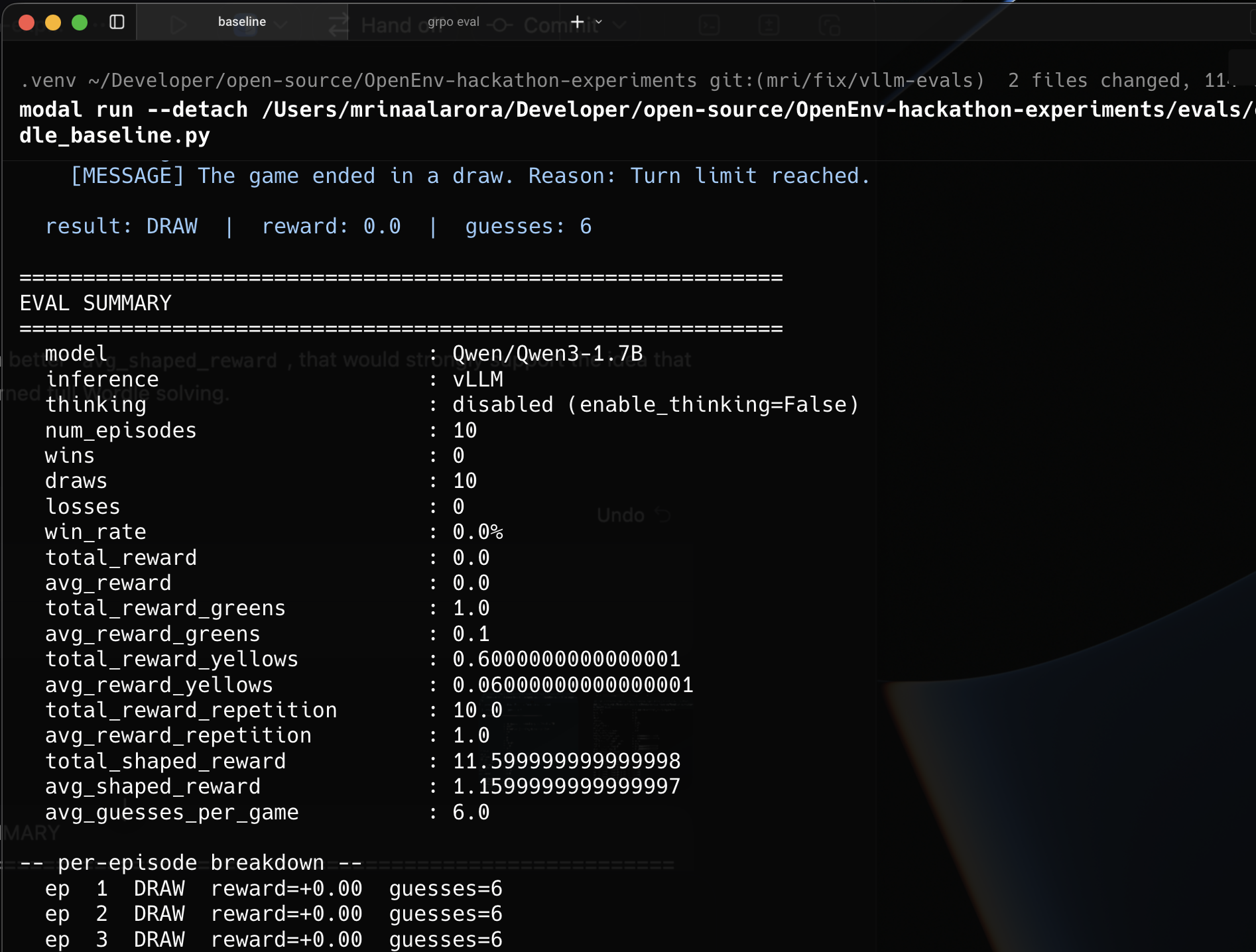
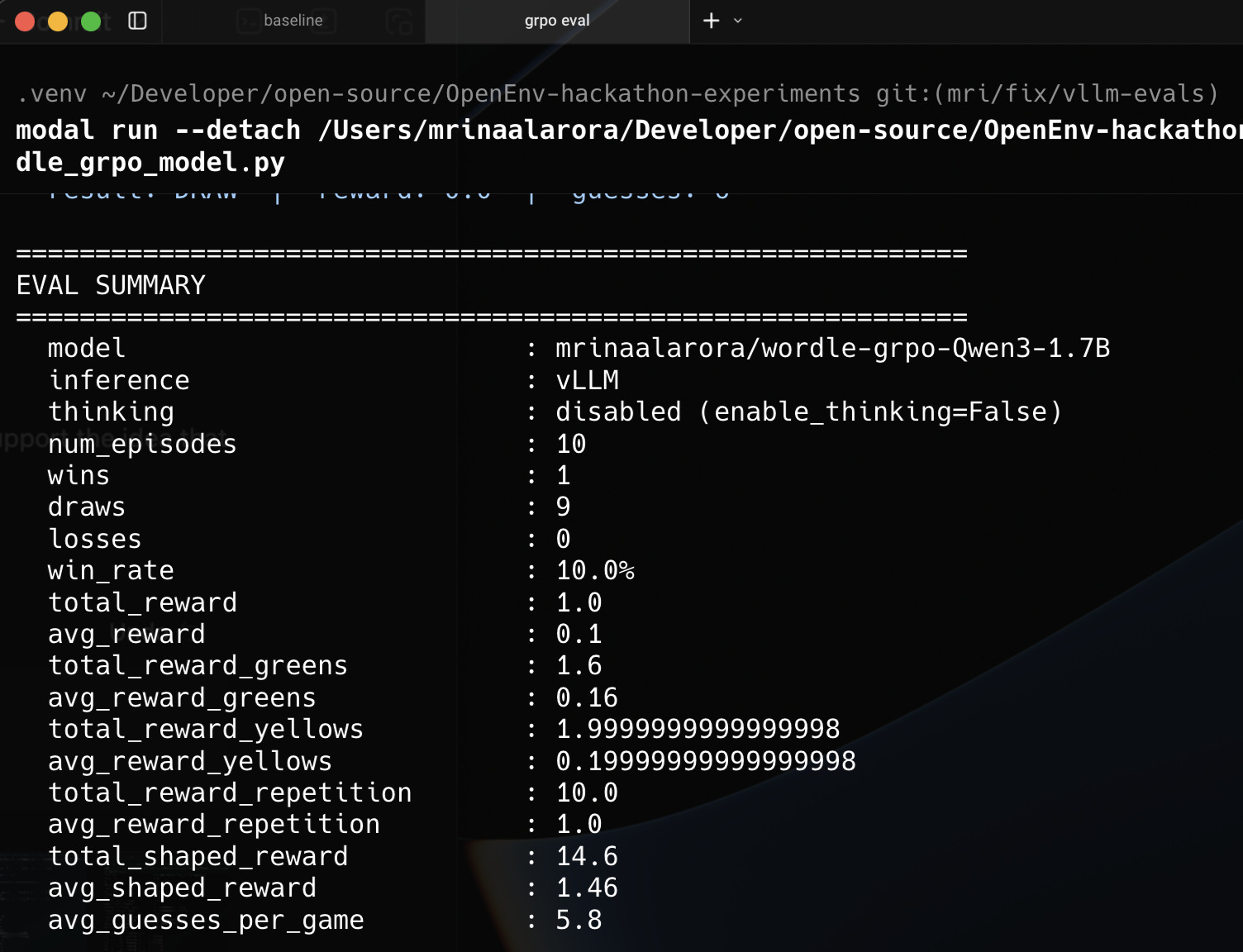
Baseline Qwen3-1.7B, with no RL, had 0 wins in 10 episodes. The GRPO fine tuned model got 1 win in 10.
That is a tiny sample, so I also looked at the 50 episode runs.
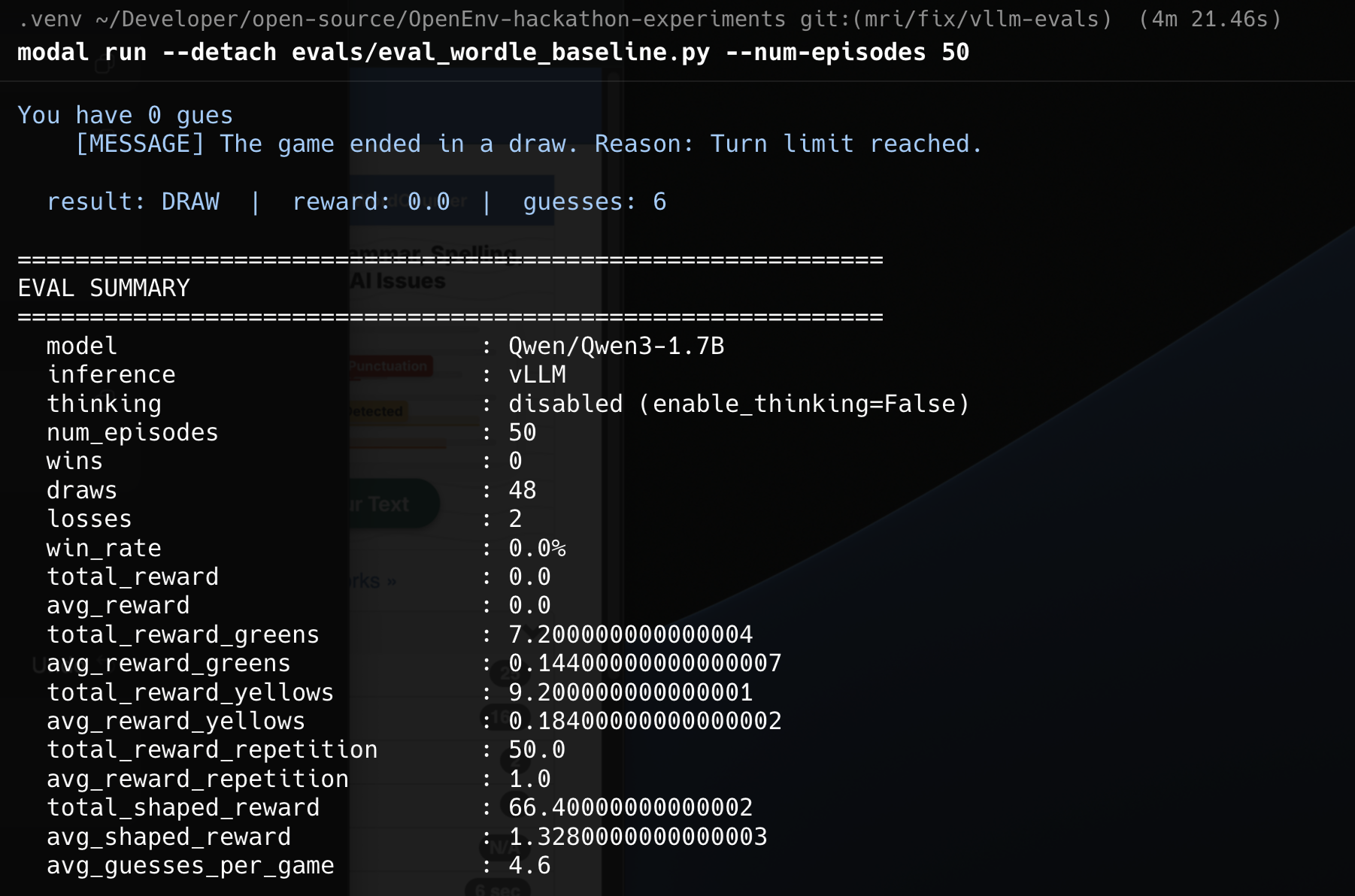
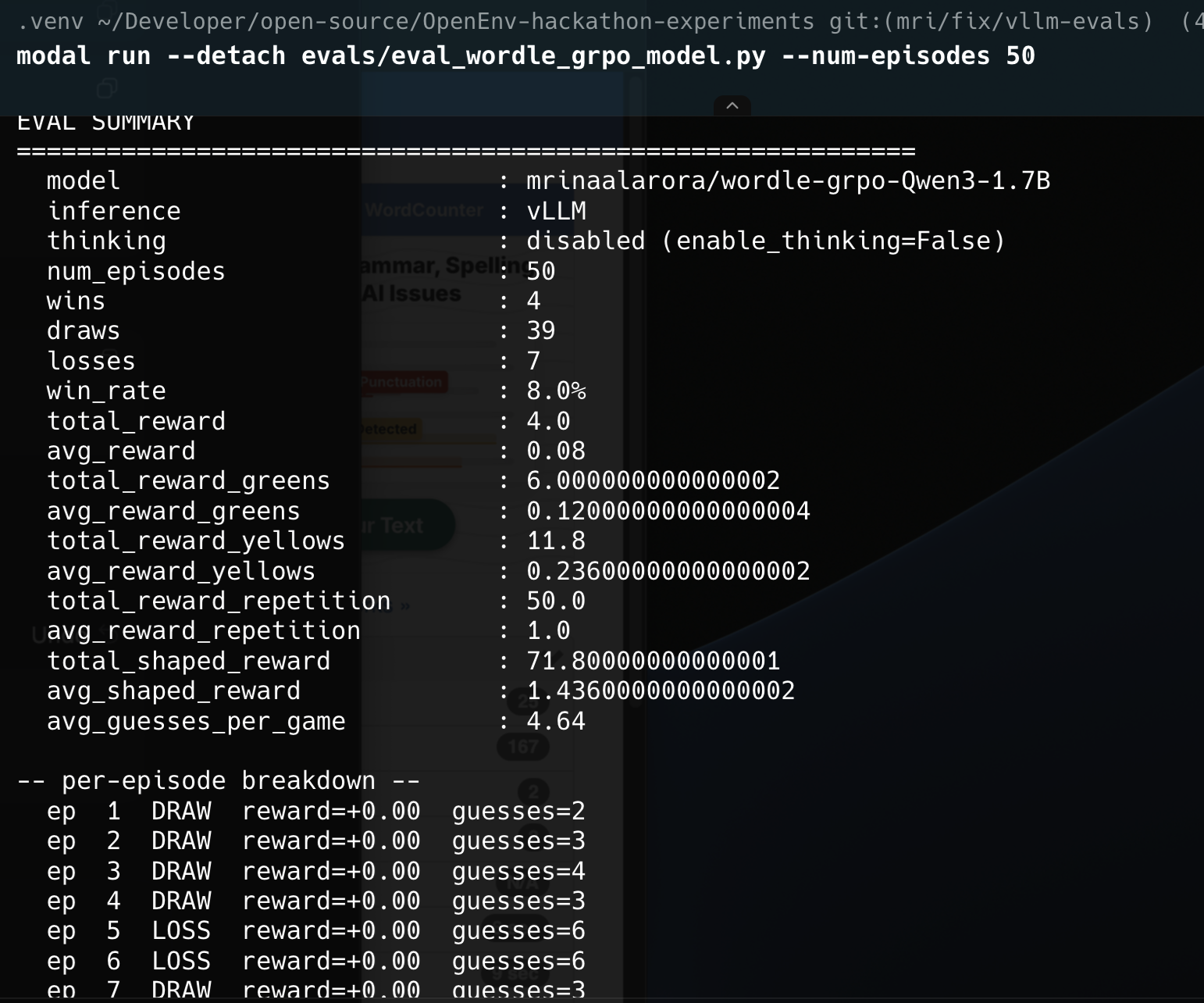
That comparison is the one I trust much more:
- Baseline win rate:
0%
- GRPO fine tuned win rate:
8%
- Average shaped reward:
1.328 to 1.436
- Average yellow reward:
0.184 to 0.236
Not every metric becomes prettier after RL, and I actually like that this result is not too clean. Average greens did not jump in some dramatic way. The model is still far from "good at Wordle." But it is clearly better than the baseline, and the direction lines up with what the training curves already suggested. The model learned useful gameplay behavior first, and that started translating into occasional wins.
Why This Worked Better Than My Previous RL Runs
The biggest lesson for me is that this run sat in a much better place than the previous two RL projects.
The first RL blog had a reward setup that eventually became too fragile. The second RL blog taught me that even with cleaner hosted infra, the task itself can be at the wrong difficulty range for RL.
Wordle through this setup felt different for two reasons.
First, the reward was shaped in a way that kept the learning signal alive. Repetition reward, greens, yellows, and correctness gave the model multiple ways to improve, instead of asking it to jump directly from "bad" to "solved."
Second, the task difficulty was actually learnable for this model. Not trivial from step zero. Not impossible either. It sat in a middle range where GRPO had something real to optimize.
That is honestly why this feels like my first successful RL training run, not just my third RL run.
OpenEnv Made The Right Thing Feel Natural
Something else I appreciated a lot here is that OpenEnv pushed me toward a cleaner architecture without making it feel heavy. The environment lived as a service, the trainer lived separately, and the model updated by talking to the environment over the network. That separation made the whole thing feel much closer to how I now think RL environments should be built for agents and LLMs. Not giant monolith scripts. Small isolated systems that expose a clean interface and can be swapped, duplicated, or hosted independently.
That part is important to me because this run is not the end goal. This was more like my warm up run before building the actual original OpenEnv environment I want to make for the hackathon.
This One Meant A Lot To Me
I do not want to over dramatize a small Wordle run, but I also do not want to undersell what it felt like.
This was the first time I trained something with RL and saw the reward go up in a way that made intuitive sense to me. Not because I copied a chart from a paper. Not because I stared at a benchmark table. Because I actually ran the system myself, watched the curves, ran the evals, and understood the loop.
So big thanks to Ben Burtenshaw for the TextArena environment and for the OpenEnv tutorial that made it possible to move this quickly.
I have spent around $62 worth of GPU time on Modal this month for my ML experiments.
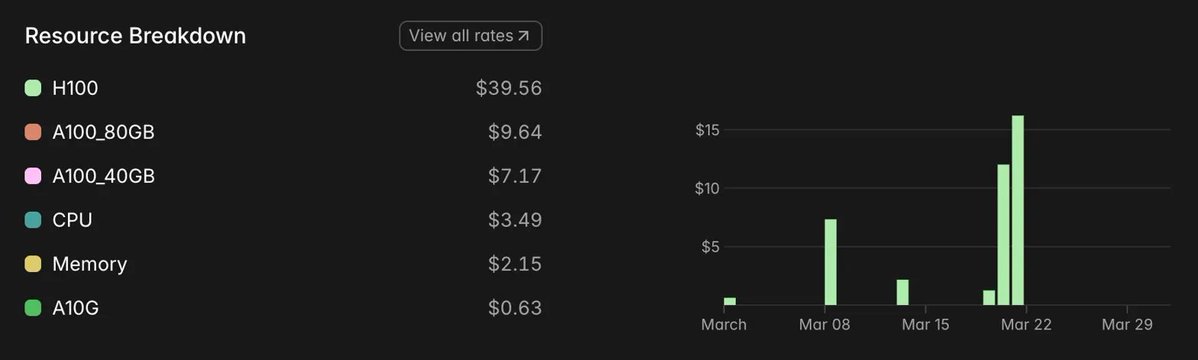
And honestly, seeing this next image after the run made me smile a little.
A couple of weeks back I did not even know what RL actually meant, let alone how an RL environment should be structured. Now I have a run where a small model learned something real from interaction. That feels like a pretty good place to stop this one.
See you in the next one hopefully with the first RL environment that i have created.
Links
Previous RL Blogs
OpenEnv And Hackathon
Model And Training Stack
Why This One Felt Different
The hidden reason I ended up here is honestly the last two RL blogs.
In my first RL experiment, I learned what it feels like when a reward function quietly stops being useful. In my second RL experiment, I learned that even if the infra is cleaner, the task can still be too easy or too hard for GRPO to have anything meaningful to do.
So by the time I started this one, I was not just randomly trying another RL run. I was specifically looking for my first successful RL training run, meaning a run where the reward actually trends up, the system stays healthy, and I can explain to myself why it improved. That is what this turned into. I trained Qwen3-1.7B to play Wordle using Hugging Face TRL's
GRPOTrainer, connected to a live TextArena Wordle environment running on a Hugging Face Space.After a couple of weeks of learning RL from scratch, this was the first time I got a reward curve that actually went up because of something I trained and understood end to end.
How I Got Pulled Into OpenEnv
Part of the reason this happened now is that I am participating in the Meta x PyTorch x Hugging Face hackathon by Scaler School of Technology. The hackathon goal is to build an RL environment for agents and LLMs using the new OpenEnv framework.
That was the moment I stopped thinking only about "how do I run GRPO?" and started thinking more about what an RL environment even is.
The core OpenEnv idea clicked for me in a very software engineering way. RL environments should be microservices. You do not need to run your database inside the same process as your web server. Same idea here. The environment can live in its own isolated Docker container, exposed through HTTP or WebSocket APIs, and the training code just talks to it.
I even drew out my mental model while trying to understand it.
Once that clicked, the rest of the setup started making much more sense in my head. Modal would host the training job and the model. The environment would live separately as a service. The trainer would just send actions to it, receive observations and rewards back, and keep updating the model.
Why Wordle Became My Starter RL Environment
While going through the OpenEnv training tutorial, I came across the example that uses TRL to train a model to play Wordle through interaction and reinforcement. The moment I saw that, the idea felt too clean not to try.
Why not take a small model, connect it to a live TextArena Wordle environment, and let GRPO learn from the game loop itself?
To get started quickly, I duplicated the recommended hosted Hugging Face Space to my own account so I would have my own environment endpoint to hit during training. Before running actual RL, I first wanted to validate the whole pipe. I wrote a small script just to test the connection between my Modal container and the hosted Wordle environment.
That validation step mattered a lot for me because after the previous two RL blogs, I did not want to confuse "the environment pipe is broken" with "the RL setup is weak." I wanted at least one experiment where the infrastructure path itself felt boring in a good way.
The Training Stack
The full stack I used was simple enough that it still feels a bit unreal to me:
GRPOTrainervLLMcolocate mode for fast generation during trainingFor the model, I picked Qwen3-1.7B, exactly as mentioned in the tutorial.
One detail that also matters here: this was a full weights run, not LoRA. There was no
peft_configin theGRPOTrainercall, which means all1.7Bparameters were being updated. So the weights coming out of this run were a real fine tune. I pushed those final weights here as wordle-grpo-Qwen3-1.7B on Hugging Face.The Actual Run
The training job ran on Modal for about
1h 34mon anA100 80GB.The shape of the run was:
62gradient steps4rollouts per prompt15,800live Wordle games played during trainingThat number is what made this whole thing feel especially cool to me. This was not offline RL with some static reward labels already sitting in a dataset. The model was interacting with a live environment, making guesses, getting feedback, and slowly adjusting itself inside that loop.
My First Reward Curve That Actually Went Up
The main graph tells the story instantly.
If you want to look at the full live metrics view itself, the Trackio dashboard is here: qwen3-1.7b-grpo-62s-4r-2run.
train/rewardwent from about0.61to1.28.That is not some tiny wiggle where you have to convince yourself the run maybe worked. The reward almost doubled. After the two RL experiments before this one, just seeing that curve move in the right direction felt kind of surreal.
But the better part is that I can also explain why it went up.
The biggest driver was the repetition reward.
rewards/reward_repetition/meanmoved from around0.20to around0.95.That is real behavioral learning. The model was learning one of the first core Wordle rules: stop wasting turns by repeating guesses. This is also what made the run feel qualitatively different from my earlier RL attempts. The reward was not just some fragile parse of the last token. It had shaped components tied to actual gameplay behavior, and the model found the most learnable one first.
The correctness reward stayed much smaller, but it did start appearing.
rewards/reward_correct/meanstarted around0.0and later reached roughly0.015to0.031. So no, the model did not suddenly become a monster Wordle agent. But it did start solving games occasionally, and the first real signs of that showed up around step14.The greens and yellows rewards told a softer story.
Those metrics were not the dramatic part of the run. They moved, but not in the same obvious way as repetition reward. To me that makes sense. Not repeating guesses is a much easier behavioral principle to learn early than actually solving Wordle consistently. The model first learned how to avoid a dumb mistake. Only after that did it start showing rare signs of genuine solving.
The training loss also looked mechanically healthy enough throughout the run.
It was noisy, yes, but not broken. And the other logs matched that feeling too. Entropy went from about
0.13to0.47, which tells me the model got more exploratory in its guesses.sampling/IS_ratiostayed around1.0all62steps, which is exactly the kind of boring number I wanted to see. Boring is good when you are trying to trust the mechanics.Did It Actually Play Better
I did not want to stop at the training dashboard, so I ran evals separately using
vLLMon Modal as well.The quick
10episode eval already showed the direction.Baseline
Qwen3-1.7B, with no RL, had0wins in10episodes. The GRPO fine tuned model got1win in10.That is a tiny sample, so I also looked at the
50episode runs.That comparison is the one I trust much more:
0%8%1.328to1.4360.184to0.236Not every metric becomes prettier after RL, and I actually like that this result is not too clean. Average greens did not jump in some dramatic way. The model is still far from "good at Wordle." But it is clearly better than the baseline, and the direction lines up with what the training curves already suggested. The model learned useful gameplay behavior first, and that started translating into occasional wins.
Why This Worked Better Than My Previous RL Runs
The biggest lesson for me is that this run sat in a much better place than the previous two RL projects.
The first RL blog had a reward setup that eventually became too fragile. The second RL blog taught me that even with cleaner hosted infra, the task itself can be at the wrong difficulty range for RL.
Wordle through this setup felt different for two reasons.
First, the reward was shaped in a way that kept the learning signal alive. Repetition reward, greens, yellows, and correctness gave the model multiple ways to improve, instead of asking it to jump directly from "bad" to "solved."
Second, the task difficulty was actually learnable for this model. Not trivial from step zero. Not impossible either. It sat in a middle range where GRPO had something real to optimize.
That is honestly why this feels like my first successful RL training run, not just my third RL run.
OpenEnv Made The Right Thing Feel Natural
Something else I appreciated a lot here is that OpenEnv pushed me toward a cleaner architecture without making it feel heavy. The environment lived as a service, the trainer lived separately, and the model updated by talking to the environment over the network. That separation made the whole thing feel much closer to how I now think RL environments should be built for agents and LLMs. Not giant monolith scripts. Small isolated systems that expose a clean interface and can be swapped, duplicated, or hosted independently.
That part is important to me because this run is not the end goal. This was more like my warm up run before building the actual original OpenEnv environment I want to make for the hackathon.
This One Meant A Lot To Me
I do not want to over dramatize a small Wordle run, but I also do not want to undersell what it felt like.
This was the first time I trained something with RL and saw the reward go up in a way that made intuitive sense to me. Not because I copied a chart from a paper. Not because I stared at a benchmark table. Because I actually ran the system myself, watched the curves, ran the evals, and understood the loop.
So big thanks to Ben Burtenshaw for the TextArena environment and for the OpenEnv tutorial that made it possible to move this quickly.
I have spent around
$62worth of GPU time on Modal this month for my ML experiments.And honestly, seeing this next image after the run made me smile a little.
A couple of weeks back I did not even know what RL actually meant, let alone how an RL environment should be structured. Now I have a run where a small model learned something real from interaction. That feels like a pretty good place to stop this one.
See you in the next one hopefully with the first RL environment that i have created.
Links
Previous RL Blogs
OpenEnv And Hackathon
Model And Training Stack
GRPOTrainerdocumentation