Why I Ran A Second RL Experiment
In my first RL experiment, I ran GRPO on GSM8K using TRL on Modal with Qwen2.5 1.5B Instruct. That run taught me a lot, especially about fragile reward parsers, format drift, and how quickly a small model can go off the rails when the reward function stops being informative. But even after writing that post, one thing still felt unresolved in my head. I still had not seen a reward curve that just cleanly goes up from start to finish.
That was the real reason for this second run. I wanted to get closer to a setup where the infra disappears into the background and the actual experiment design becomes the main thing. So for this round I moved from custom Modal plus TRL code to Prime Intellect Lab, which is much more config driven. The whole idea was simple. Remove infra friction, reduce the number of moving parts, and get closer to the actual question: can I find a task and a model where GRPO has real signal and a real chance to improve reward over time?
Why Prime Intellect Lab Felt Different
The first blog used Modal as infra and I wrote the training logic myself. That was very good for learning, but it also means every experiment has a lot of surface area for bugs. With Prime Intellect Lab the whole thing flips. You write a TOML config, point it at a model and an environment, and run one command.
prime rl run configs/rl/gsm8k.toml
That is it. No GPU setup. No container plumbing. No custom reward parser code just to get a run started. The gap between "I have an idea" and "the experiment is running" becomes one config file, which honestly felt like a literal CHEATCODE.
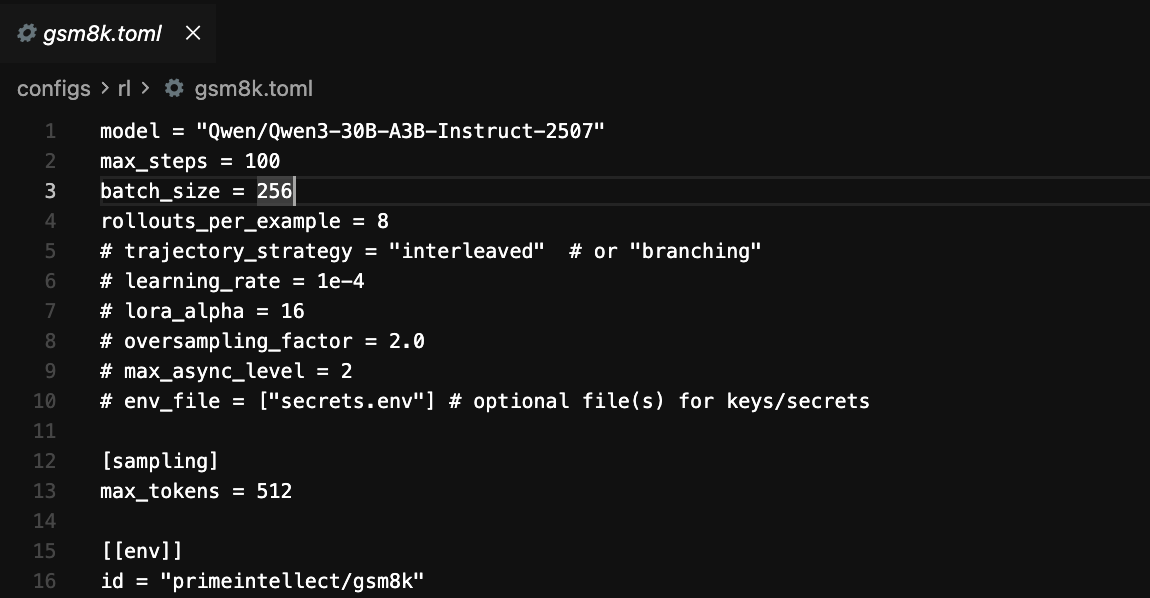
The config I ended up using for the completed GSM8K run lives here:
The environment itself was primeintellect/gsm8k, a pre built single turn environment from the hub. It handles the dataset loading, the prompt formatting, and the exact match reward function. Under the hood this whole approach sits on the verifiers library, which is basically the layer that makes these RL environments composable in the first place.
Experiment 1: Too Hard From The Start
Before jumping to GSM8K, I tried the alphabet sort environment using a very small model, meta-llama/Llama-3.2-1B-Instruct. On paper it felt like a nice starter experiment. In practice it failed almost immediately.
The key problem was task difficulty relative to model capability. Alphabet sort in this environment is multi turn, and with a 1B model plus short generation limits, almost every rollout was effectively useless. If all rollouts in the group are equally bad, GRPO has nothing to compare. No contrast means no real learning signal.
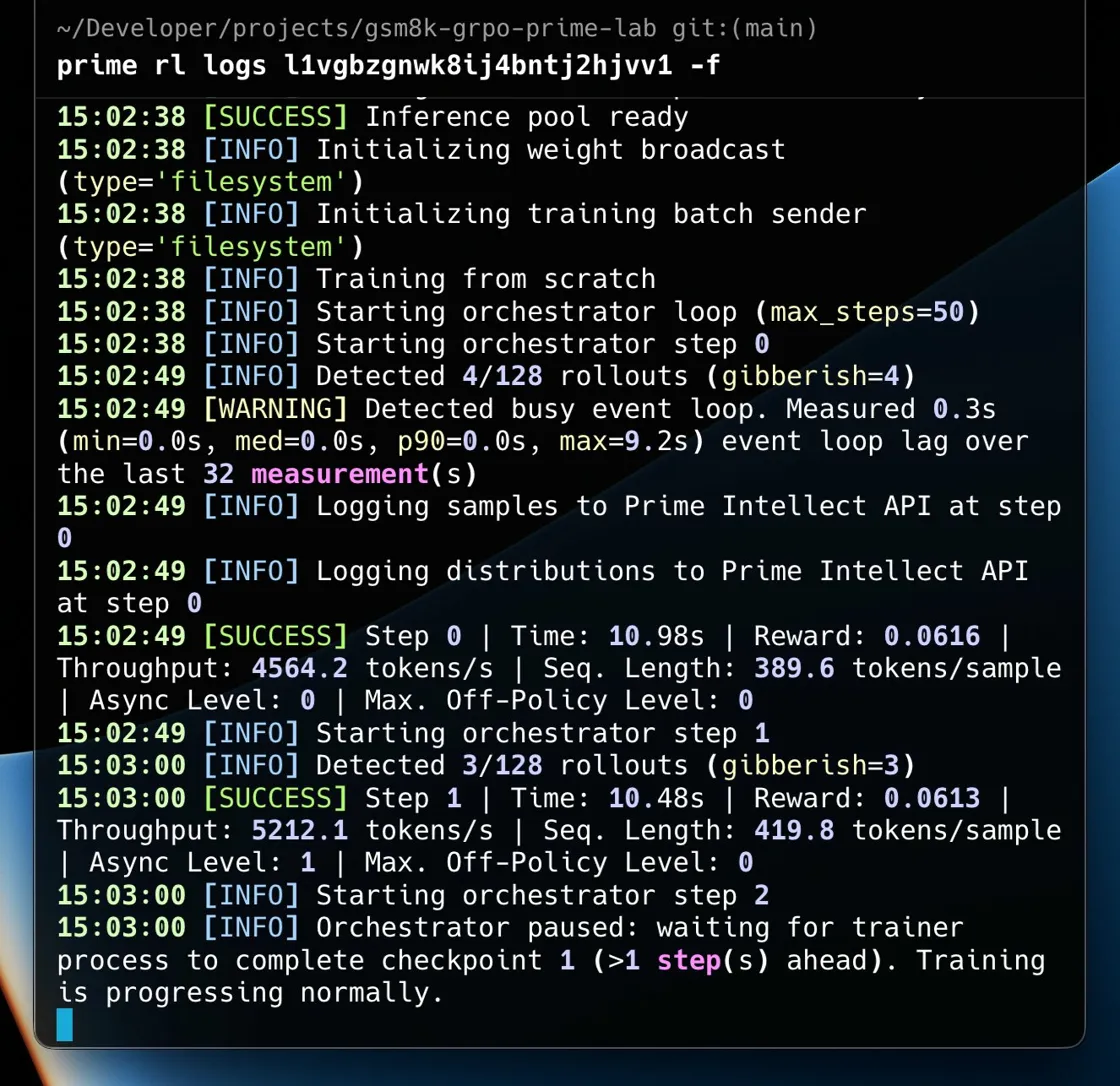
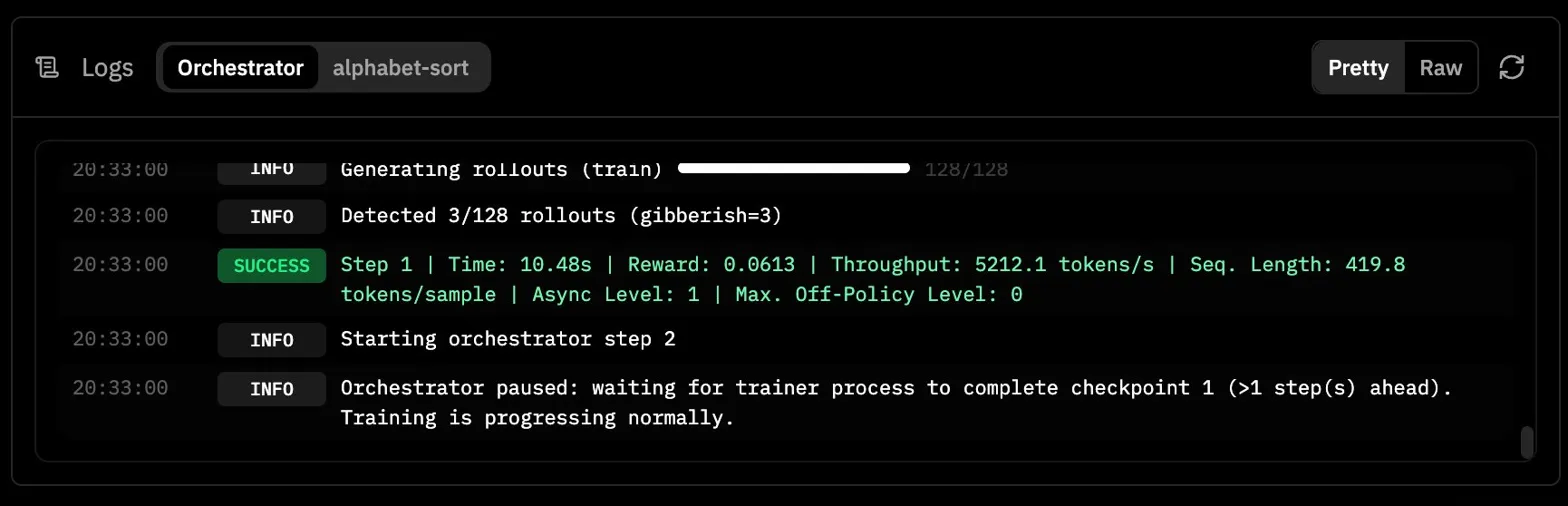
What made this confusing at first was that the run did not look broken in the obvious way. The environment installed correctly, the server became healthy, step 0 completed, step 1 completed, and then the run just kind of paused. The logs said the orchestrator was waiting for the trainer process to complete checkpoint 1, but after that everything went quiet.
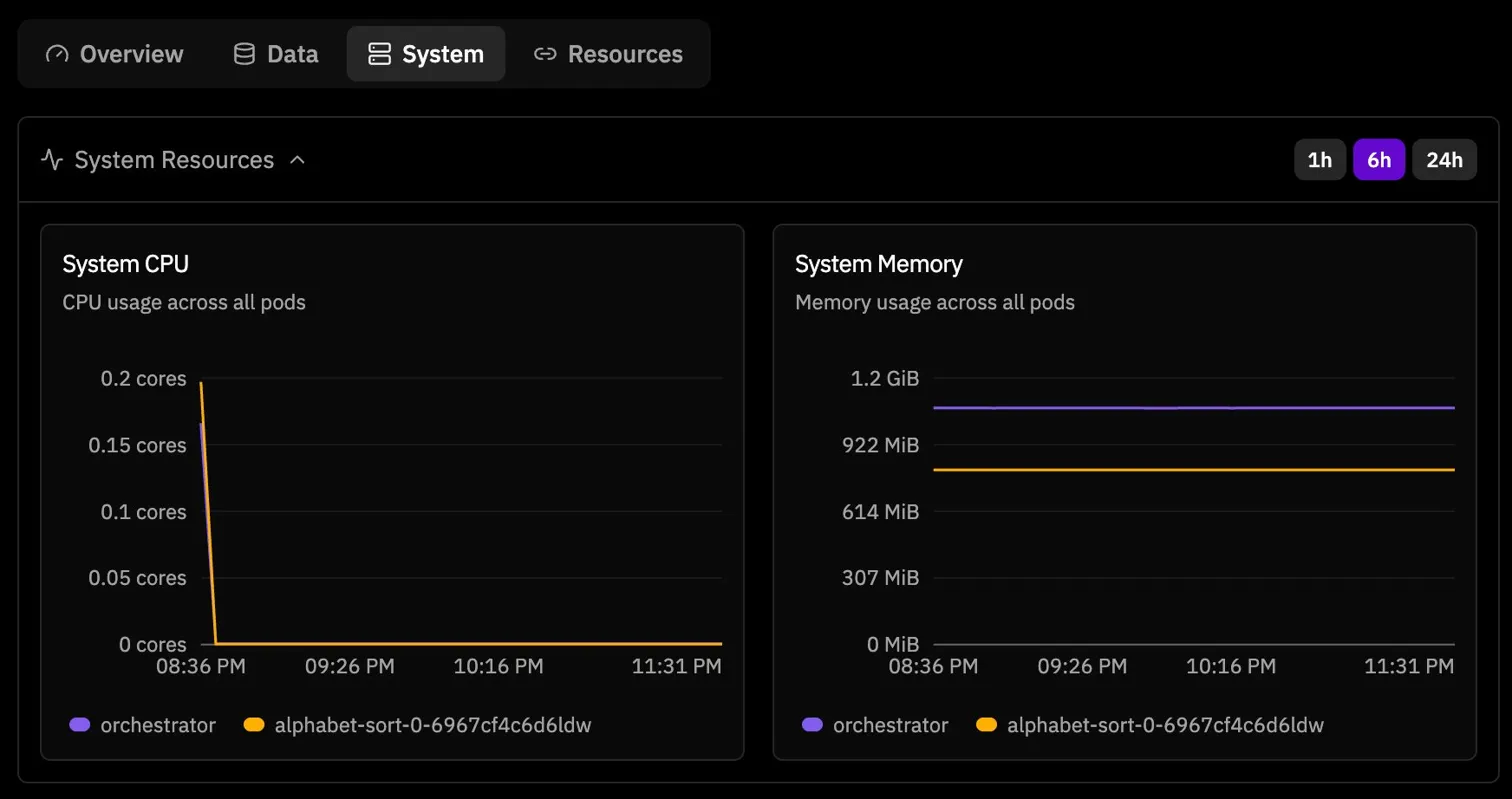
At that moment I honestly suspected some hosted training pipeline issue. The run looked alive but not productive. Then the system metrics made the stall even more obvious. CPU dropped to zero while memory stayed allocated, which is exactly the kind of screenshot that makes you stare at the dashboard and wonder if the model is learning or just existing.
Looking back, my current read is that this was a combination of task difficulty and smaller model fragility. Whether you call it a platform edge case, a small model instability issue, or just a bad experimental setup, the big lesson was the same. GRPO needs variance inside the group. If every rollout gets the same terrible reward, the update has nowhere to go.
Baseline Evals Changed Everything
Before spending more time on training, I did something I should have done much earlier. I ran hosted evals first.
That one step changed the entire direction of the experiment. On the GSM8K environment, the baseline numbers were already telling a full story:
meta-llama/Llama-3.2-3B-Instruct: 0.780allenai/OLMo-3-7B-Instruct: 0.980Qwen/Qwen3-4B-Instruct-2507: 0.980
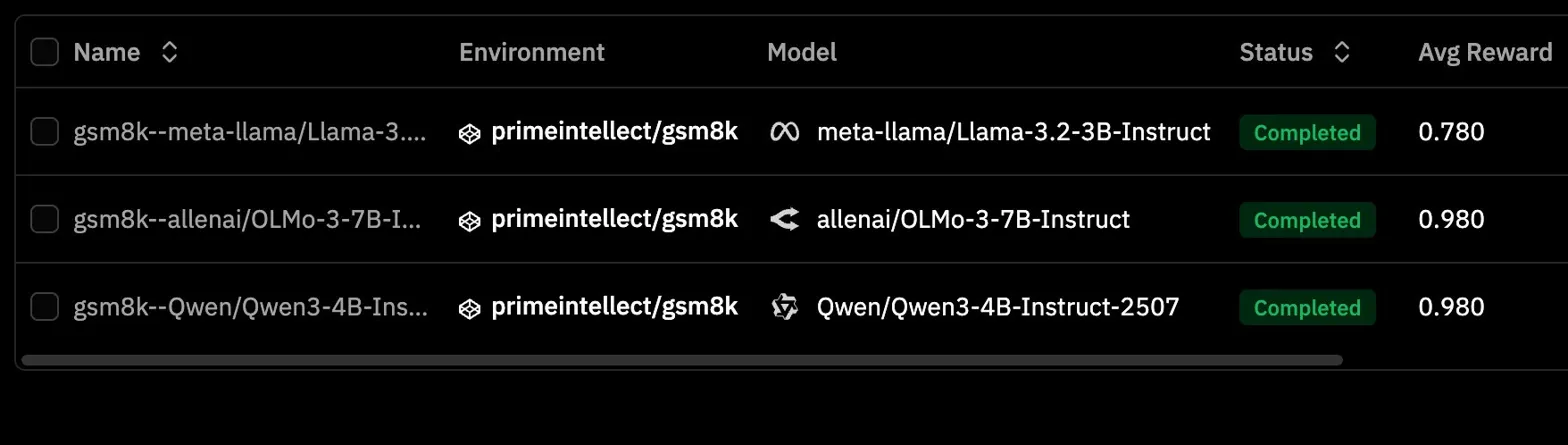
The 0.98 results were wild at first, but they also made perfect sense once I sat with them. This is what modern post training has done to the field. GSM8K is basically a solved benchmark for a lot of models in this size range. From an RL perspective that creates a different problem. If the model already starts near ceiling, the reward curve has almost nowhere to go.
That immediately made Llama 3.2 3B Instruct look like the most interesting candidate. 0.780 is not bad, but it still leaves meaningful failure cases. In theory that should be enough room for GRPO to actually learn something.
Experiment 2: Even The Smaller GSM8K Run Felt Fragile
So I simplified the setup and tried the smaller dense model on GSM8K too. This was the config shape I was using for the Llama 3.2 3B Instruct run.
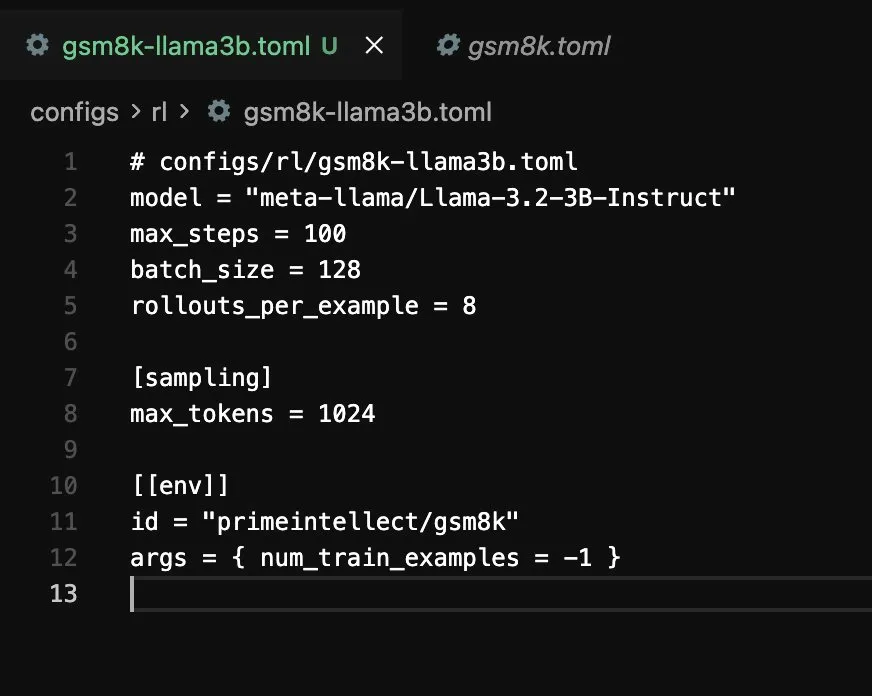
I kept simplifying the config because I wanted to rule out the possibility that I had done something structurally wrong. Smaller batch sizes, smaller models, fewer moving pieces, cleaner config. But the overall feeling stayed the same. Dense 1B to 3B models felt much more fragile under GRPO on this setup than I expected.
That was another new learning for me. Architecture matters here, not just benchmark capability. If you only think in terms of "how smart is the model," you miss a very practical RL question: how stable is this model under training?
Experiment 3: The Clean 30B Run
At that point I decided to stop chasing the ideal run and just aim for a clean, completed one. I picked Qwen/Qwen3-30B-A3B-Instruct-2507 on GSM8K, partly because it was available, partly because it is a Mixture of Experts model, and partly because I just wanted to see the whole system run end to end without stalls.
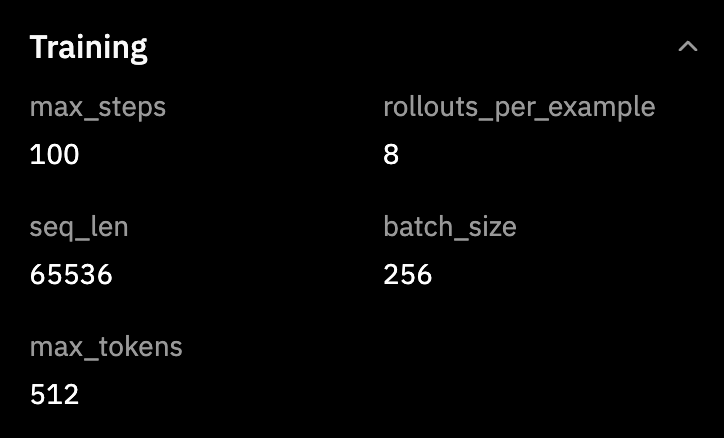
The training settings were simple and honestly pretty generous:
And the final run summary looked like this:
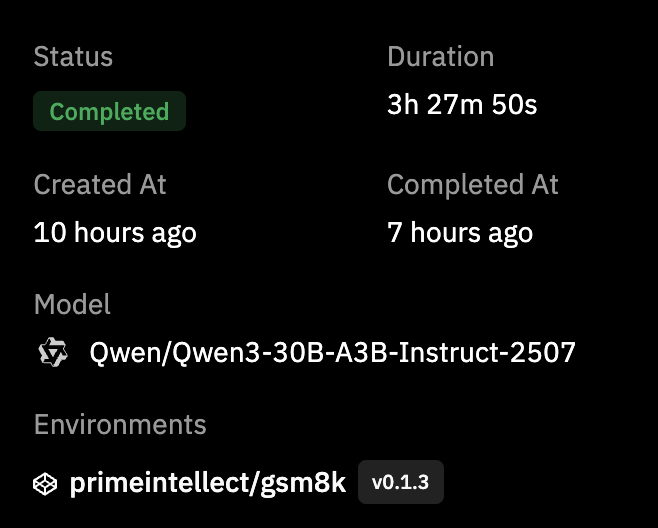
This was genuinely satisfying. Full completion. No hangs. No crash. About 3h 27m end to end. After the smaller model attempts, just seeing a clean finished run felt good.
The reward curve, though, told a much more subtle story. It started at 0.949 on step 0.
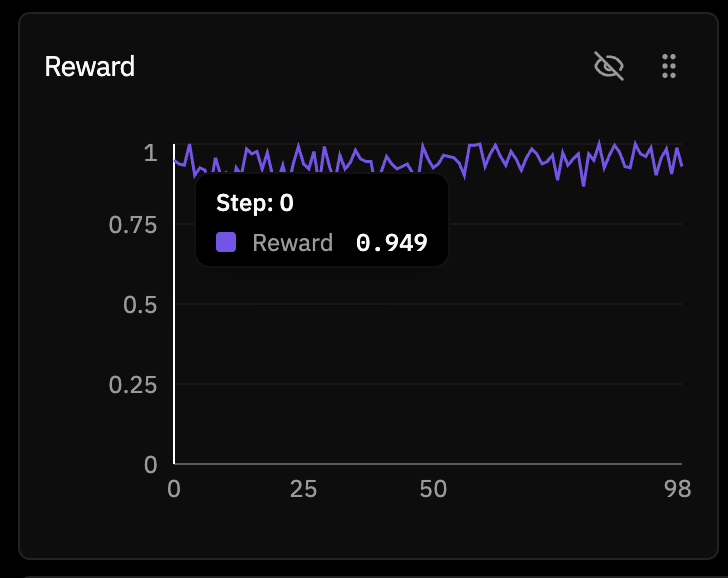
And by the end it had only moved to 0.988.
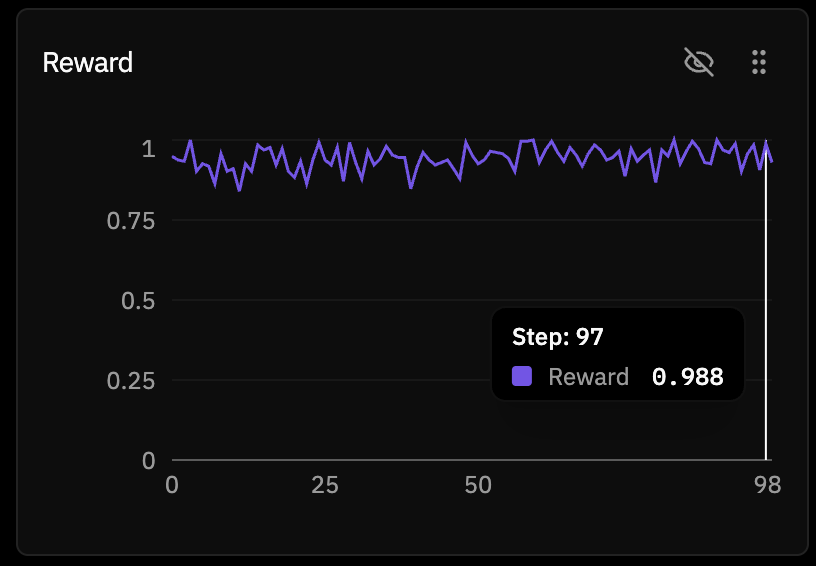
So yes, technically the reward did go up. But it barely had any room to. This was not the satisfying rising reward curve I had been chasing in my head. It was a basically solved task on a near ceiling model. GRPO was working correctly. The model just had very little left to learn from the reward function.
The Goldilocks Dilemma
That is when the real pattern became obvious to me.
I had now hit both bad extremes:
- Too hard: tiny model on a task where almost every rollout gets
0, which means no contrast and no learning signal
- Too easy: very strong model on a solved task, where reward starts around
0.95 and there is almost no room left to improve
What I actually need is the middle. The Goldilocks zone. A task where the model starts somewhere around 30% to 70%, so there are enough failures to learn from, but not so many failures that every rollout is equally bad.
That part sounds obvious once you say it out loud, but in practice it is genuinely hard. Modern small and mid sized models are already so good on standard benchmarks that finding this learnable middle is its own research problem. I think that was the biggest lesson of this whole second experiment.
What Prime Intellect Lab Got Right
Separate from the experimental results, I actually liked the platform. A lot.
The biggest thing for me was that it removed a huge amount of infra friction. Hosted evals before training were very useful. The clean 30B run really did complete cleanly. The config based workflow is much simpler than custom infra. And the available models list is already interesting enough that I could feel the surface area for experiments opening up while using it.
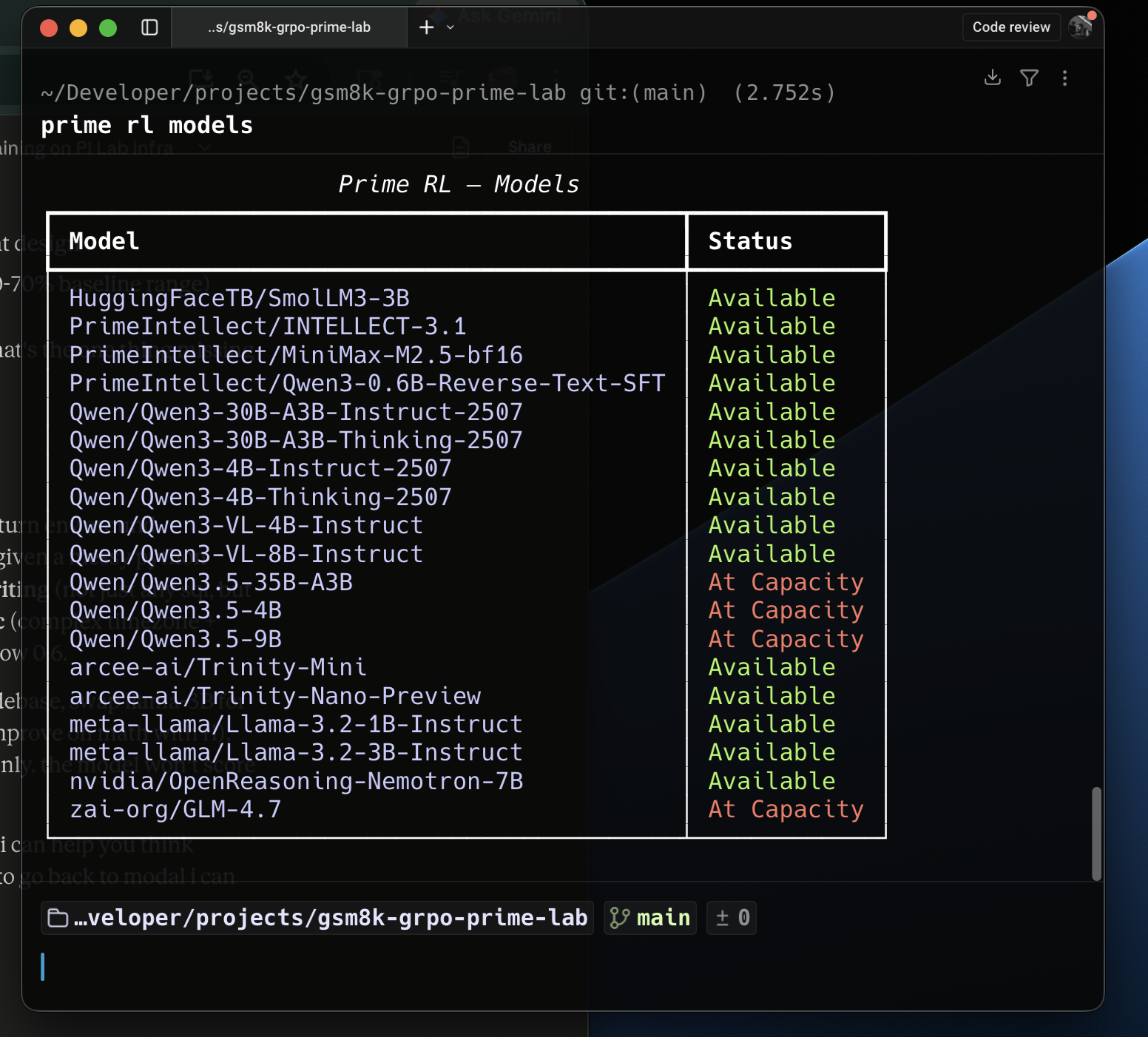
If someone wants to explore it, these are the main docs and entry points I found useful:
So my conclusion on the platform itself is positive. The infrastructure mostly did what I wanted. The harder part was not "how do I launch GRPO?" It was "how do I design an experiment where GRPO has something meaningful to do?"
What I Want To Build Next
This experiment made the next step feel obvious. I think I need to stop trying to squeeze signal out of standard environments and instead build an RL environment from scratch for a task where the model is genuinely not already very good.
The pattern I want now is:
- Pick a niche task that is not already a solved benchmark
- Make sure the task still has deterministic ground truth
- Run evals first and only proceed if the baseline sits in the learnable middle
- Build the environment with the verifiers library
- Only then run GRPO
The basic environment shape in my head now looks like this:
import verifiers as vf
def load_environment():
rubric = vf.Rubric(
funcs=[format_reward, correctness_reward],
weights=[1.0, 1.0],
)
return vf.SingleTurnEnv(
dataset=train_dataset,
eval_dataset=eval_dataset,
system_prompt=SYSTEM_PROMPT,
rubric=rubric,
)
That feels like the natural sequel to this whole phase. The first RL blog taught me what happens when the reward function cannot keep up with the model. This second one taught me that even with a clean hosted setup, you still need the task itself to sit in the right range. The reward curve that really goes up cleanly is still something I have not personally seen yet. That is what I am chasing next.
What These Two RL Experiments Taught Me
Looking back at both this post and the first RL blog, a few things feel very clear to me now.
- The Goldilocks problem is real. Finding a task that is neither too easy nor too hard is a big part of the work.
- GRPO, like in the DeepSeek paper, needs variance inside the group. If all rollouts are equally bad or equally good, the update becomes almost meaningless.
- Model architecture matters for stability, not just raw benchmark performance. Smaller dense models felt much more fragile here than the larger MoE model.
- Baseline eval before training is not optional. It should be step zero, not an afterthought.
- In RL, the reward function really is the experiment. In the first blog the parser drifted out of sync. In this one the tasks themselves sat at the wrong difficulty extremes. Different failure mode, same deeper truth.
That is honestly why I still find RL so interesting. Every time I think I am just running another experiment, it turns out I am actually learning something more basic about the setup itself.
See you in the Next one!!!
Links
Previous And Current Work
Prime Intellect
Datasets And Papers
Why I Ran A Second RL Experiment
In my first RL experiment, I ran GRPO on GSM8K using TRL on Modal with Qwen2.5 1.5B Instruct. That run taught me a lot, especially about fragile reward parsers, format drift, and how quickly a small model can go off the rails when the reward function stops being informative. But even after writing that post, one thing still felt unresolved in my head. I still had not seen a reward curve that just cleanly goes up from start to finish.
That was the real reason for this second run. I wanted to get closer to a setup where the infra disappears into the background and the actual experiment design becomes the main thing. So for this round I moved from custom Modal plus TRL code to Prime Intellect Lab, which is much more config driven. The whole idea was simple. Remove infra friction, reduce the number of moving parts, and get closer to the actual question: can I find a task and a model where GRPO has real signal and a real chance to improve reward over time?
Why Prime Intellect Lab Felt Different
The first blog used Modal as infra and I wrote the training logic myself. That was very good for learning, but it also means every experiment has a lot of surface area for bugs. With Prime Intellect Lab the whole thing flips. You write a TOML config, point it at a model and an environment, and run one command.
That is it. No GPU setup. No container plumbing. No custom reward parser code just to get a run started. The gap between "I have an idea" and "the experiment is running" becomes one config file, which honestly felt like a literal CHEATCODE.
The config I ended up using for the completed GSM8K run lives here:
The environment itself was primeintellect/gsm8k, a pre built single turn environment from the hub. It handles the dataset loading, the prompt formatting, and the exact match reward function. Under the hood this whole approach sits on the verifiers library, which is basically the layer that makes these RL environments composable in the first place.
Experiment 1: Too Hard From The Start
Before jumping to GSM8K, I tried the alphabet sort environment using a very small model,
meta-llama/Llama-3.2-1B-Instruct. On paper it felt like a nice starter experiment. In practice it failed almost immediately.The key problem was task difficulty relative to model capability. Alphabet sort in this environment is multi turn, and with a 1B model plus short generation limits, almost every rollout was effectively useless. If all rollouts in the group are equally bad, GRPO has nothing to compare. No contrast means no real learning signal.
What made this confusing at first was that the run did not look broken in the obvious way. The environment installed correctly, the server became healthy, step 0 completed, step 1 completed, and then the run just kind of paused. The logs said the orchestrator was waiting for the trainer process to complete checkpoint 1, but after that everything went quiet.
At that moment I honestly suspected some hosted training pipeline issue. The run looked alive but not productive. Then the system metrics made the stall even more obvious. CPU dropped to zero while memory stayed allocated, which is exactly the kind of screenshot that makes you stare at the dashboard and wonder if the model is learning or just existing.
Baseline Evals Changed Everything
Before spending more time on training, I did something I should have done much earlier. I ran hosted evals first.
That one step changed the entire direction of the experiment. On the GSM8K environment, the baseline numbers were already telling a full story:
meta-llama/Llama-3.2-3B-Instruct:0.780allenai/OLMo-3-7B-Instruct:0.980Qwen/Qwen3-4B-Instruct-2507:0.980The
0.98results were wild at first, but they also made perfect sense once I sat with them. This is what modern post training has done to the field. GSM8K is basically a solved benchmark for a lot of models in this size range. From an RL perspective that creates a different problem. If the model already starts near ceiling, the reward curve has almost nowhere to go.That immediately made
Llama 3.2 3B Instructlook like the most interesting candidate.0.780is not bad, but it still leaves meaningful failure cases. In theory that should be enough room for GRPO to actually learn something.Experiment 2: Even The Smaller GSM8K Run Felt Fragile
So I simplified the setup and tried the smaller dense model on GSM8K too. This was the config shape I was using for the
Llama 3.2 3B Instructrun.I kept simplifying the config because I wanted to rule out the possibility that I had done something structurally wrong. Smaller batch sizes, smaller models, fewer moving pieces, cleaner config. But the overall feeling stayed the same. Dense
1Bto3Bmodels felt much more fragile under GRPO on this setup than I expected.That was another new learning for me. Architecture matters here, not just benchmark capability. If you only think in terms of "how smart is the model," you miss a very practical RL question: how stable is this model under training?
Experiment 3: The Clean 30B Run
At that point I decided to stop chasing the ideal run and just aim for a clean, completed one. I picked
Qwen/Qwen3-30B-A3B-Instruct-2507on GSM8K, partly because it was available, partly because it is a Mixture of Experts model, and partly because I just wanted to see the whole system run end to end without stalls.The training settings were simple and honestly pretty generous:
And the final run summary looked like this:
This was genuinely satisfying. Full completion. No hangs. No crash. About
3h 27mend to end. After the smaller model attempts, just seeing a clean finished run felt good.The reward curve, though, told a much more subtle story. It started at
0.949on step 0.And by the end it had only moved to
0.988.The Goldilocks Dilemma
That is when the real pattern became obvious to me.
I had now hit both bad extremes:
0, which means no contrast and no learning signal0.95and there is almost no room left to improveWhat I actually need is the middle. The Goldilocks zone. A task where the model starts somewhere around
30%to70%, so there are enough failures to learn from, but not so many failures that every rollout is equally bad.That part sounds obvious once you say it out loud, but in practice it is genuinely hard. Modern small and mid sized models are already so good on standard benchmarks that finding this learnable middle is its own research problem. I think that was the biggest lesson of this whole second experiment.
What Prime Intellect Lab Got Right
Separate from the experimental results, I actually liked the platform. A lot.
The biggest thing for me was that it removed a huge amount of infra friction. Hosted evals before training were very useful. The clean 30B run really did complete cleanly. The config based workflow is much simpler than custom infra. And the available models list is already interesting enough that I could feel the surface area for experiments opening up while using it.
If someone wants to explore it, these are the main docs and entry points I found useful:
So my conclusion on the platform itself is positive. The infrastructure mostly did what I wanted. The harder part was not "how do I launch GRPO?" It was "how do I design an experiment where GRPO has something meaningful to do?"
What I Want To Build Next
This experiment made the next step feel obvious. I think I need to stop trying to squeeze signal out of standard environments and instead build an RL environment from scratch for a task where the model is genuinely not already very good.
The pattern I want now is:
The basic environment shape in my head now looks like this:
That feels like the natural sequel to this whole phase. The first RL blog taught me what happens when the reward function cannot keep up with the model. This second one taught me that even with a clean hosted setup, you still need the task itself to sit in the right range. The reward curve that really goes up cleanly is still something I have not personally seen yet. That is what I am chasing next.
What These Two RL Experiments Taught Me
Looking back at both this post and the first RL blog, a few things feel very clear to me now.
That is honestly why I still find RL so interesting. Every time I think I am just running another experiment, it turns out I am actually learning something more basic about the setup itself.
See you in the Next one!!!
Links
Previous And Current Work
Prime Intellect
Datasets And Papers