Why I Took This Up
I decided to take part in the Efficient Qwen competition at AdaptFM, happening at ICML 2026. The full challenge name was Efficient Qwen: Minimizing Inference Latency for Qwen3.5-4B on A10G.
This was my first ever solo AI conference shared task effort, so I was not entering it as someone who already knew how to write CUDA kernels, quantize models properly, prune transformer layers, or do serious model distillation. I entered it because the problem statement felt very direct:
How fast can you make Qwen3.5-4B run on a single NVIDIA A10G GPU without breaking it?
I started working around June 1. The final competition deadline was June 17, 2026 AoE, which was June 18, 2026 at 5:29 PM IST. So in practice this became a very short two week sprint where I had to set up infra, understand the rules, run latency experiments, keep notes, and decide which ideas were actually worth chasing.
This felt connected to my earlier Parameter Golf experiment, but the axis changed. Parameter Golf was about making a tiny model fit inside a strict artifact size. Efficient Qwen was about taking a capable existing model and making inference faster under a real hardware budget.
The Rules
The nice thing about this challenge was that the optimization space was wide open, but the quality gates made it honest. You could use quantization, pruning, distillation from Qwen3.5-4B, architecture changes, custom CUDA or Triton kernels, custom inference engines, KV cache optimization, operator fusion, speculative decoding, torch.compile, Flash Attention variants, and memory offload.

But you could not use cached answers, benchmark detection, routing logic, eval data training, closed software, or a model stack that exceeded the original Qwen3.5-4B parameter count. Also, a single model stack had to serve the endpoints. That constraint matters a lot because otherwise it becomes easy to make one path fast for latency and another path smart for quality.
The quality gates were MMLU-Pro at least 62.1%, IFEval at least 81.4%, and GPQA-Diamond at least 63.0%. The latency score used three buckets: short prompts with 64 input tokens, medium prompts with 2048 input tokens, and long prompts with 8192 input tokens. The official baseline average was 4866 ms, and the score was average speedup over that baseline.
This is what I liked about it. It was not just "make it fast." It was "make it fast on one A10G, keep the same model family, respect the API contract, pass quality, and do not cheat."
Setting Up The Experiment Loop
I did not have a local GPU, so the first part was just getting a workflow running on remote GPU infra. I used Modal because I already had some experience with it from earlier experiments, and because it made short iteration loops less painful than keeping a machine alive manually.
The local project became a small experiment lab. I had a Modal volume with original weights, quantized weights, pruned checkpoints, KD checkpoints, and a bunch of failed or half useful variants sitting side by side.
The first useful thing was not even a model trick. It was making the experiment tracker good enough that I could trust it. Every run needed a name, exact latency numbers, what changed, what stayed fixed, and whether the result was valid or risky. Without that, 20 experiments later everything becomes mush.
My loop became:
- make one small change
- serve it on Modal A10
- smoke test the API
- run latency eval
- record the result
- kill the container
- decide if the idea moved the frontier
This is the part where I started thinking more seriously about autoresearch. The problem had a clean evaluator, a search space, a leaderboard style metric, and enough knobs that manual iteration felt slow. It reminded me of the NanoGPT speedrun style of work, where the fixed benchmark makes every small improvement visible.
The First 57 Experiments
In the first eight days I had already reached 57 total experiments. Not all of them were meaningful. Some failed during startup. Some served but were slower. Some looked smart in my head and dumb on the graph. But this was the whole point.
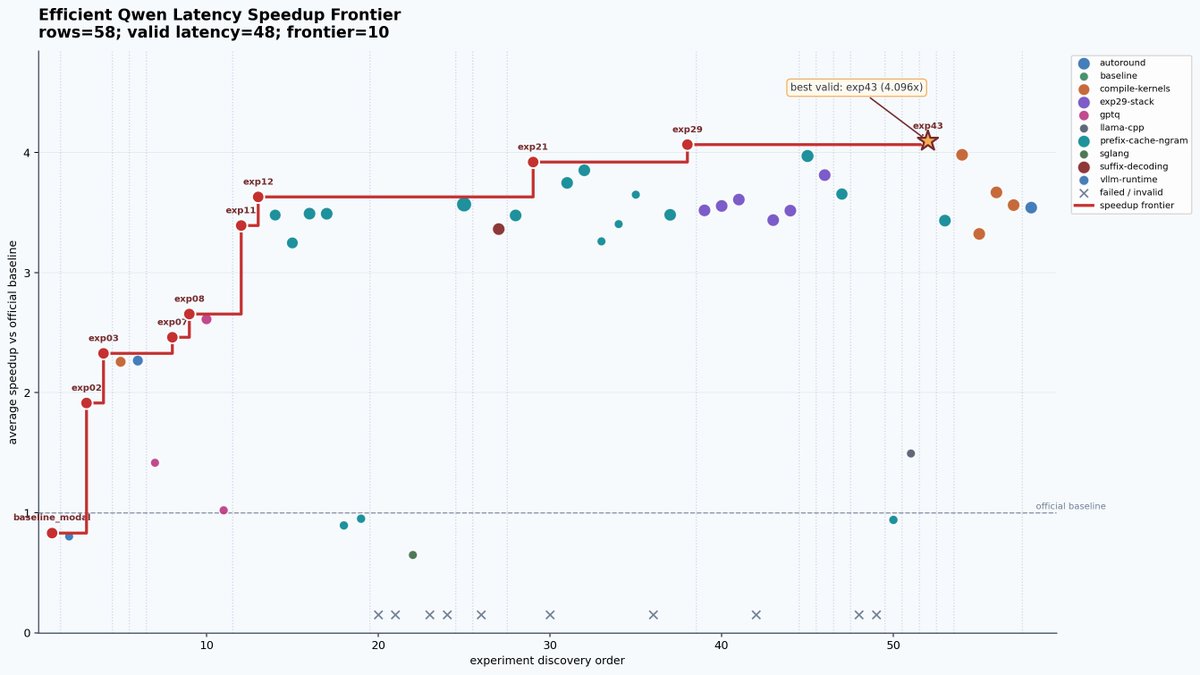
The early improvements came from stacking boring but powerful things. vLLM runtime tuning helped. N-gram speculative decoding helped a lot. GPTQ INT4 Marlin changed the weight path. Prefix caching was a very big jump. Then the later improvements became more specific: exact CUDA graph capture sizes, torch.compile, better compile ranges, and Qwen3.5 specific cache settings.
I also tried directions that did not work well. SGLang was interesting, but I kept hitting startup and kernel path issues. llama.cpp and GGUF were worth checking, but not the main path. AutoRound and AWQ were useful to understand, but the GPTQ INT4 Marlin stack was the one that kept surviving the loop.
One thing I learned here is that model latency optimization is a very humbling kind of work. A knob can sound obviously better and still regress because it changes graph capture, kernel dispatch, cache behavior, or just one ugly interaction inside the serving engine.
The Best Local Stack I Found
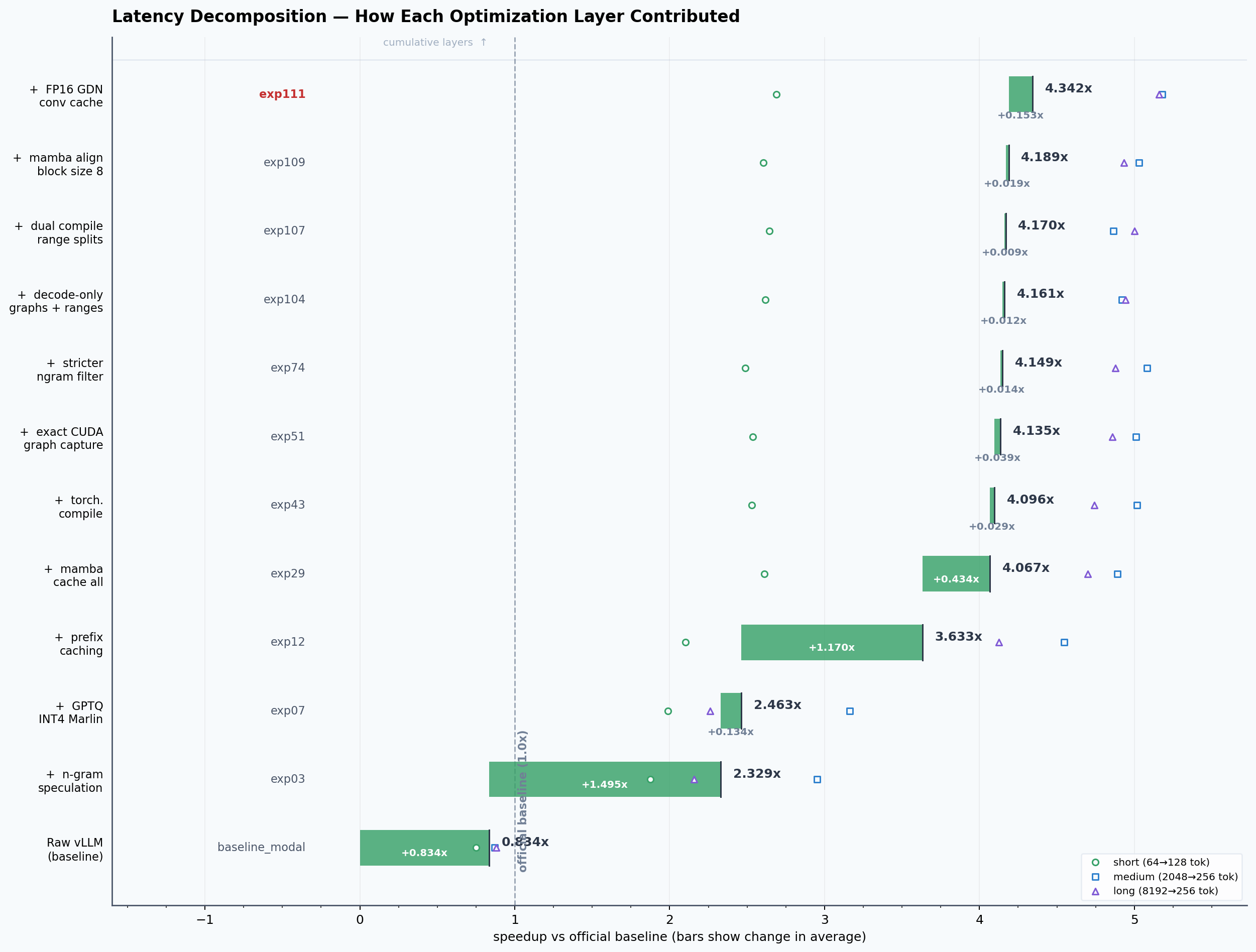
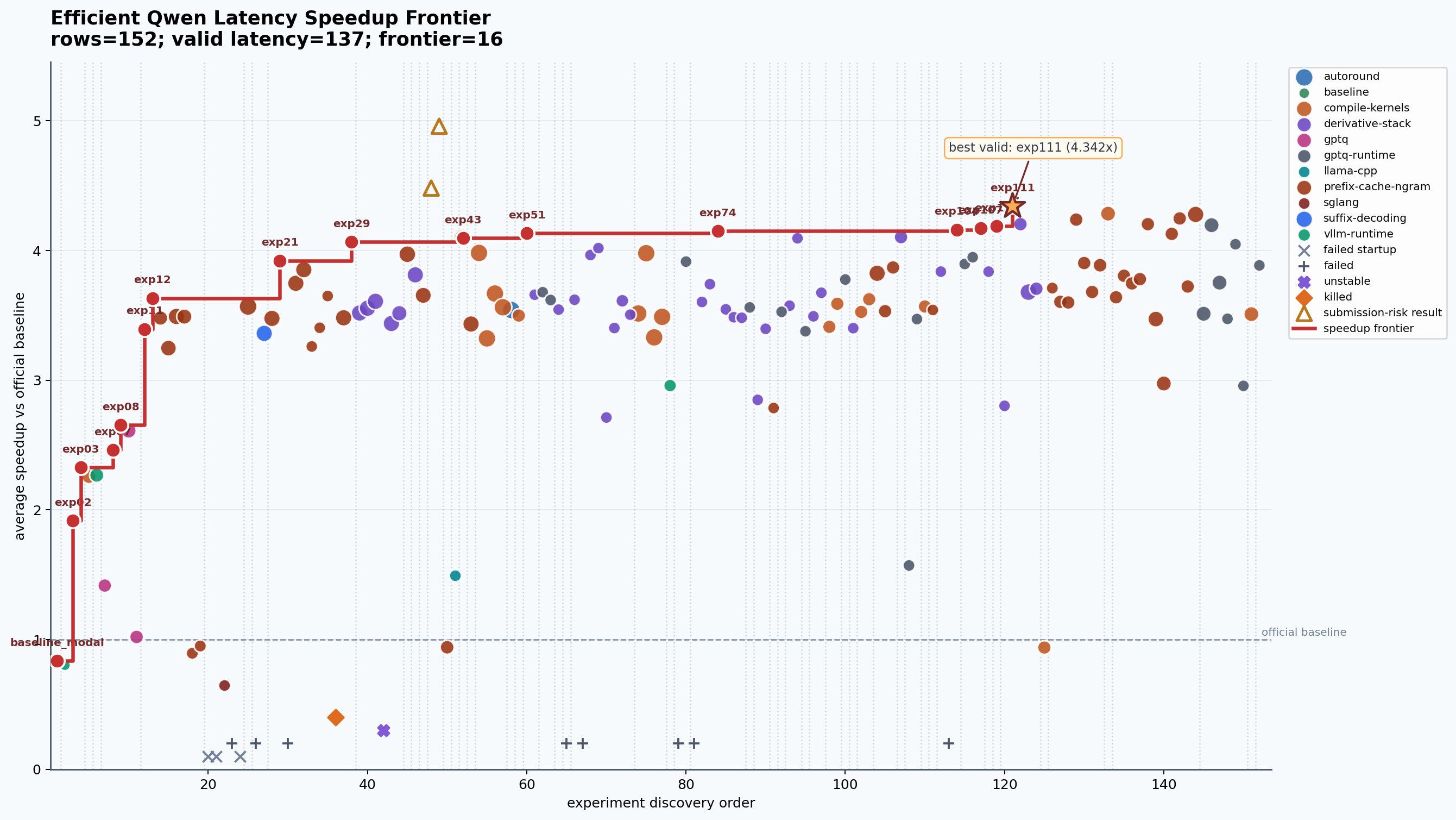
The best non risky local stack in my experiment tracker was exp111, at 4.342x average speedup on my Modal A10 latency loop. It reached around 960 ms short, 1051 ms medium, and 1274 ms long.
The stack was not one magic trick. It was a composition:
- GPTQ INT4 group size 128 weights
- vLLM
0.21.0
- prefix caching
- n-gram32 speculative decoding
torch.compile- exact CUDA graph capture around the decode shape
- dual compile ranges for medium and long prompts
- Qwen3.5 GDN cache alignment
- FP16 GDN convolution cache
This small config chain is basically the shape of the champion local setup:
def _exp111_env() -> dict[str, str]:
env = _exp109_env()
env["MAMBA_CACHE_DTYPE"] = "float16"
return env
And the serving entrypoint stayed simple:
def serve_top_champion():
_serve_process(_exp111_env())
That simplicity is a little misleading though. _exp111_env() carried a whole ancestry of earlier wins: prefix caching, speculative decoding, graph capture sizes, compile ranges, cache mode alignment, and block size tuning. The point was not that one line made the model fast. The point was that the tracker let me accumulate small wins without losing the exact recipe.
The waterfall plot made that clearer than the raw table.
The Distillation Attempt
I also ran a knowledge distillation experiment because the rules allowed distillation as long as the student was initialized from Qwen3.5-4B. That caveat is important. A separate tiny model could not just be used as a draft or student if it did not come from the original 4B weights.
My distillation idea was to repair a previously pruned student. Qwen3.5-4B has 32 text layers. I had a BI-pruned 20 layer student, where the pruning removed complete groups while trying to preserve the original attention block structure. The KD run did not remove more layers. It tried to teach the damaged 20 layer student to imitate the frozen 32 layer teacher again.

The training setup matched the student against the teacher's top 128 token probabilities, while also keeping normal next token prediction. I used FineWeb Edu streaming data and filtered out contamination terms like mmlu, gpqa, and ifeval because the quality eval benchmarks were part of the competition rules.
The core loss shape looked like this:
kd_per_token = (
teacher_top_probs
* (teacher_top_log_probs - student_top_log_probs)
).sum(dim=-1) + teacher_other_prob * (
teacher_other_log_prob - student_other_log_prob
)
This did not become my winning path, but it was one of the most useful learning parts of the sprint. Distillation stopped being just a word from papers and became a concrete thing I could run, inspect, spend money on, and mess up.
Watching The Frontier Move
By the end, I had conducted 142 major experiments, from exp01 through exp143, excluding only exp141 which was never run. This does not even count the letter variant sub-parts like 17A and 17B, or 18A through 18E. The structured experiment file had 152 rows in total, with most runs sitting around vLLM, GPTQ, prefix caching, speculative decoding, compile settings, and derivative stacks from earlier winners. A lot of dots did not matter. The frontier did.
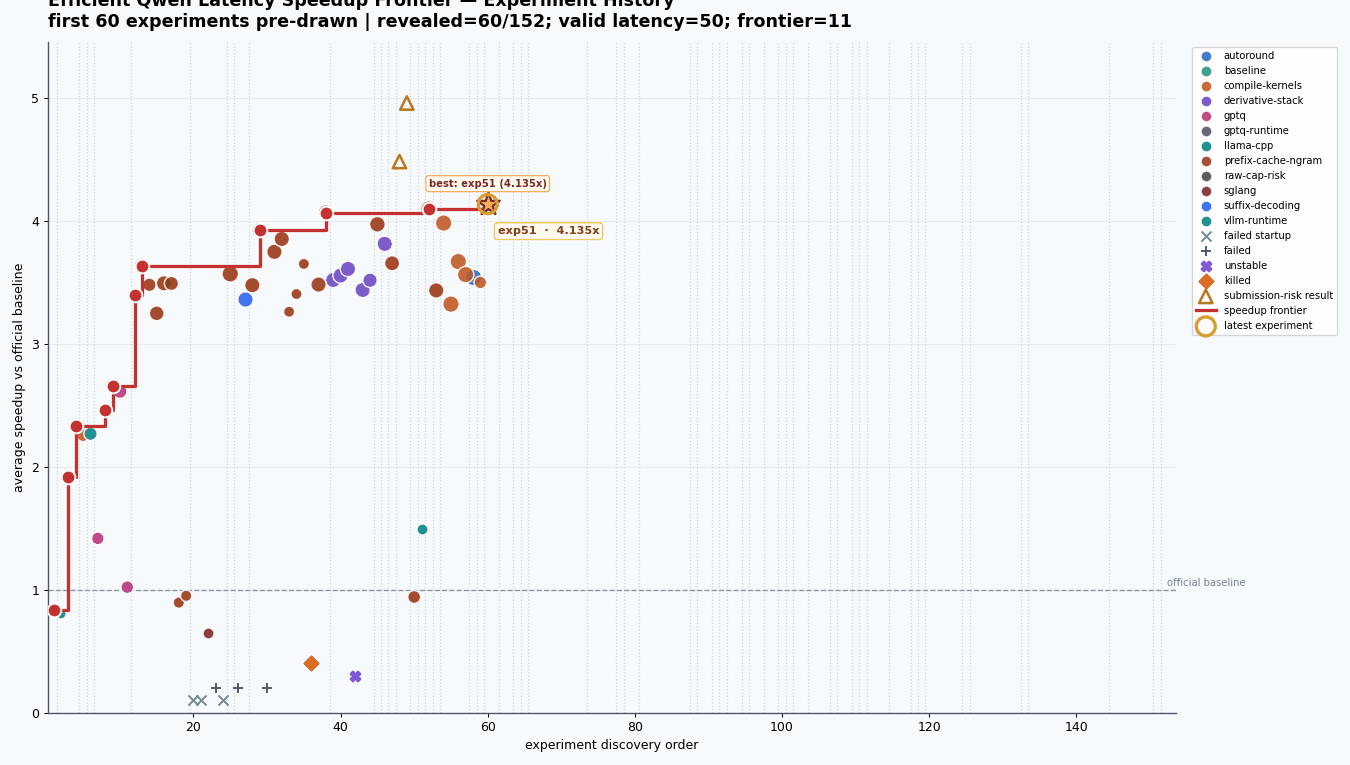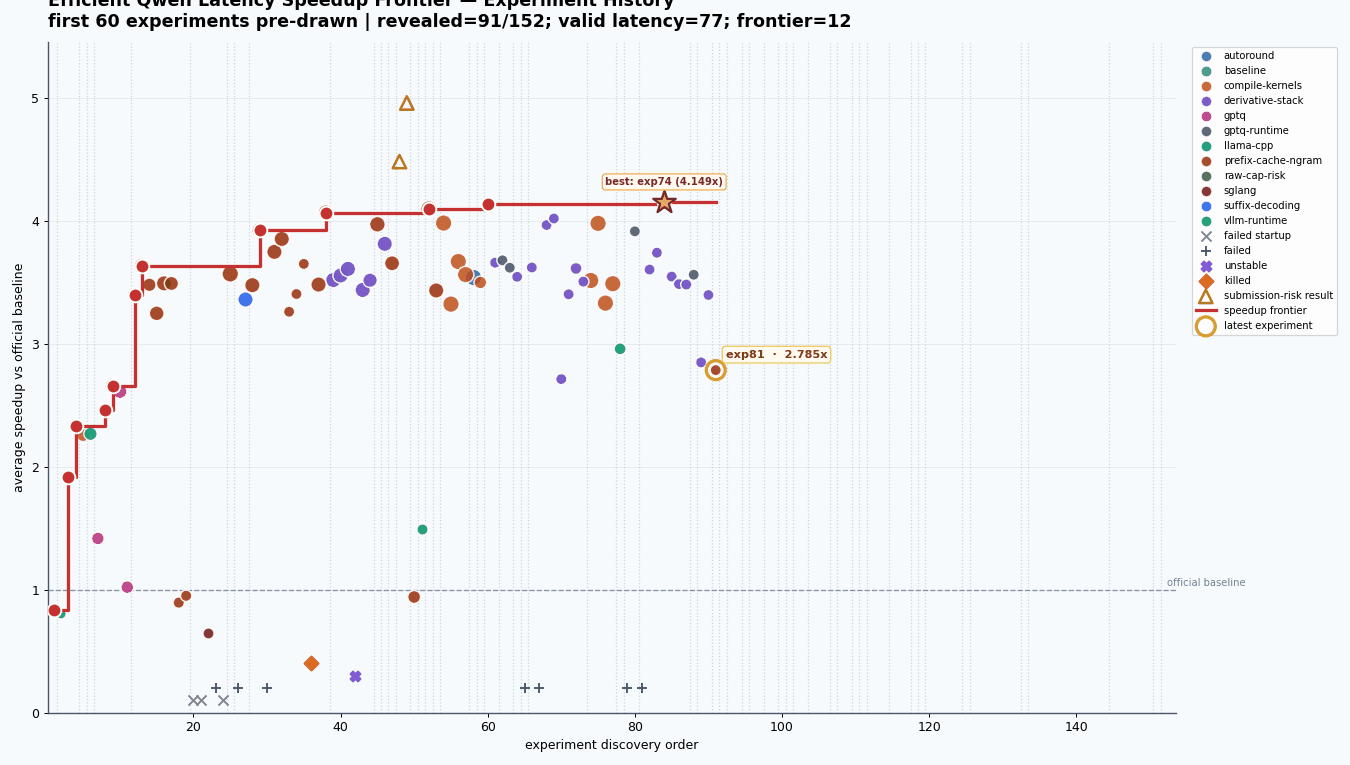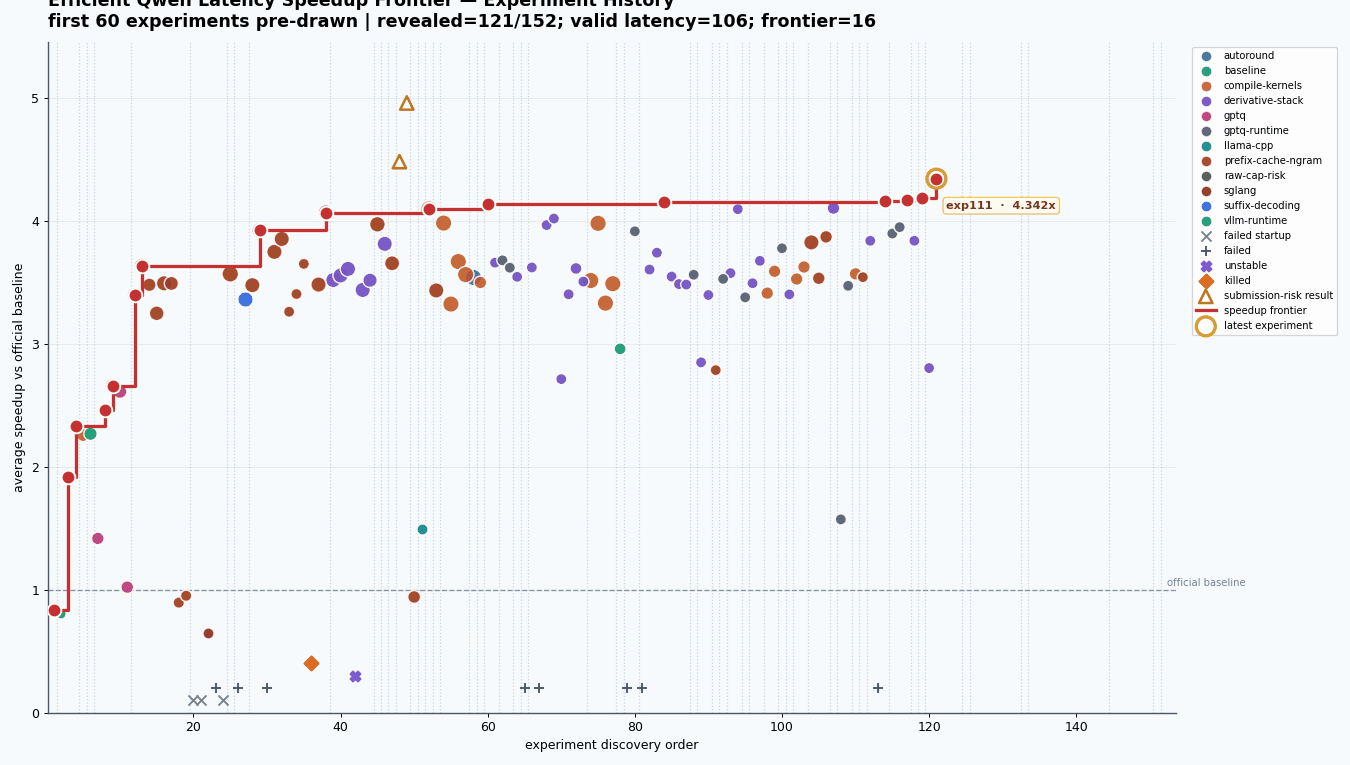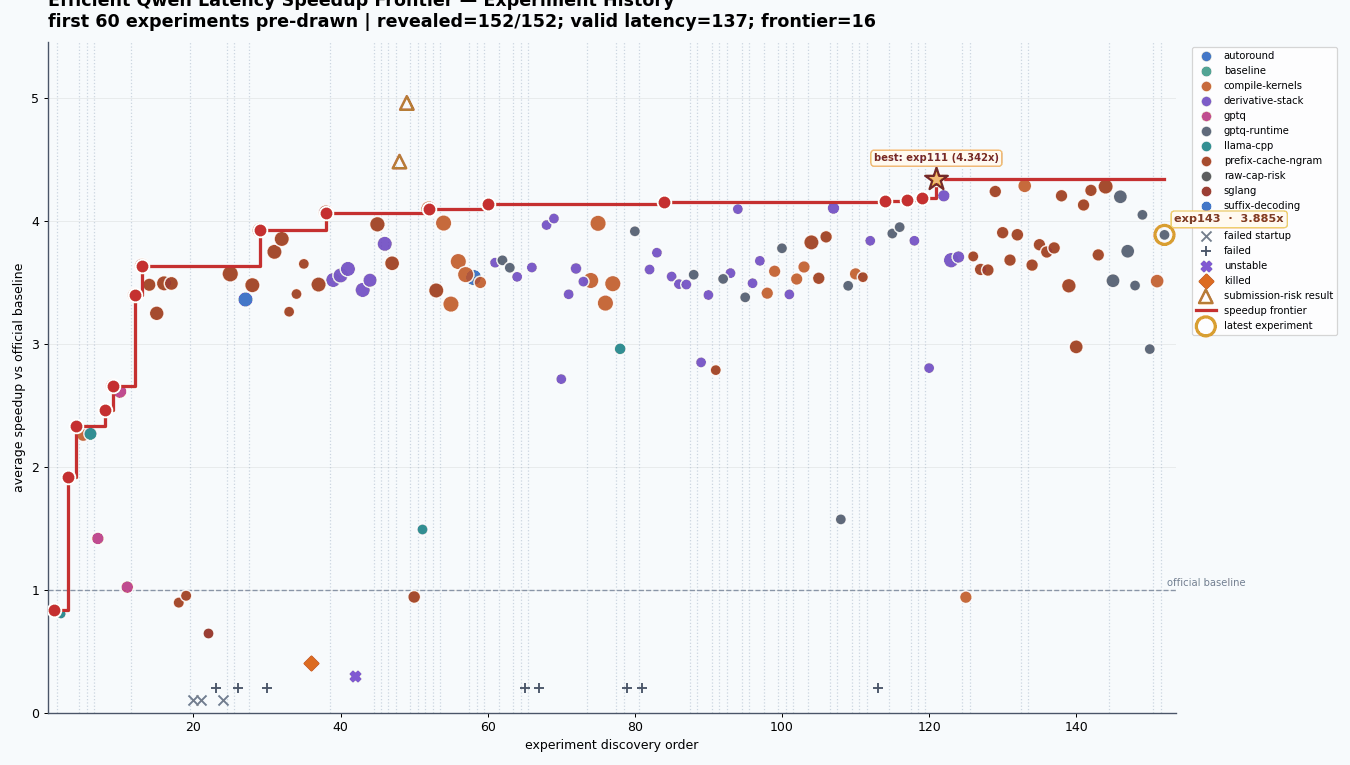
The thing I liked most was seeing how the frontier moved in jumps. exp02 made raw vLLM much faster through n-gram speculation. exp12 got a big jump from GPTQ plus prefix cache plus n-gram32. exp21, exp29, exp43, exp51, exp74, and finally exp111 each moved the best known stack a little further.
My final max clean speedup over the official baseline was 4.342x with exp111. That stack came in at around 960 ms short, 1051 ms medium, and 1274 ms long, compared with the official baseline average of 4866 ms. There were raw completion cap experiments, like exp40, that touched 4.958x, but I kept those separate because they were explicitly risky and not clean submission candidates.
I also had a few results that looked fast but were not clean for submission. This is another good lesson from challenges. A number is not enough. You have to ask: did it respect the rules, did it use the same stack, did it preserve quality, and would it survive the official evaluator?
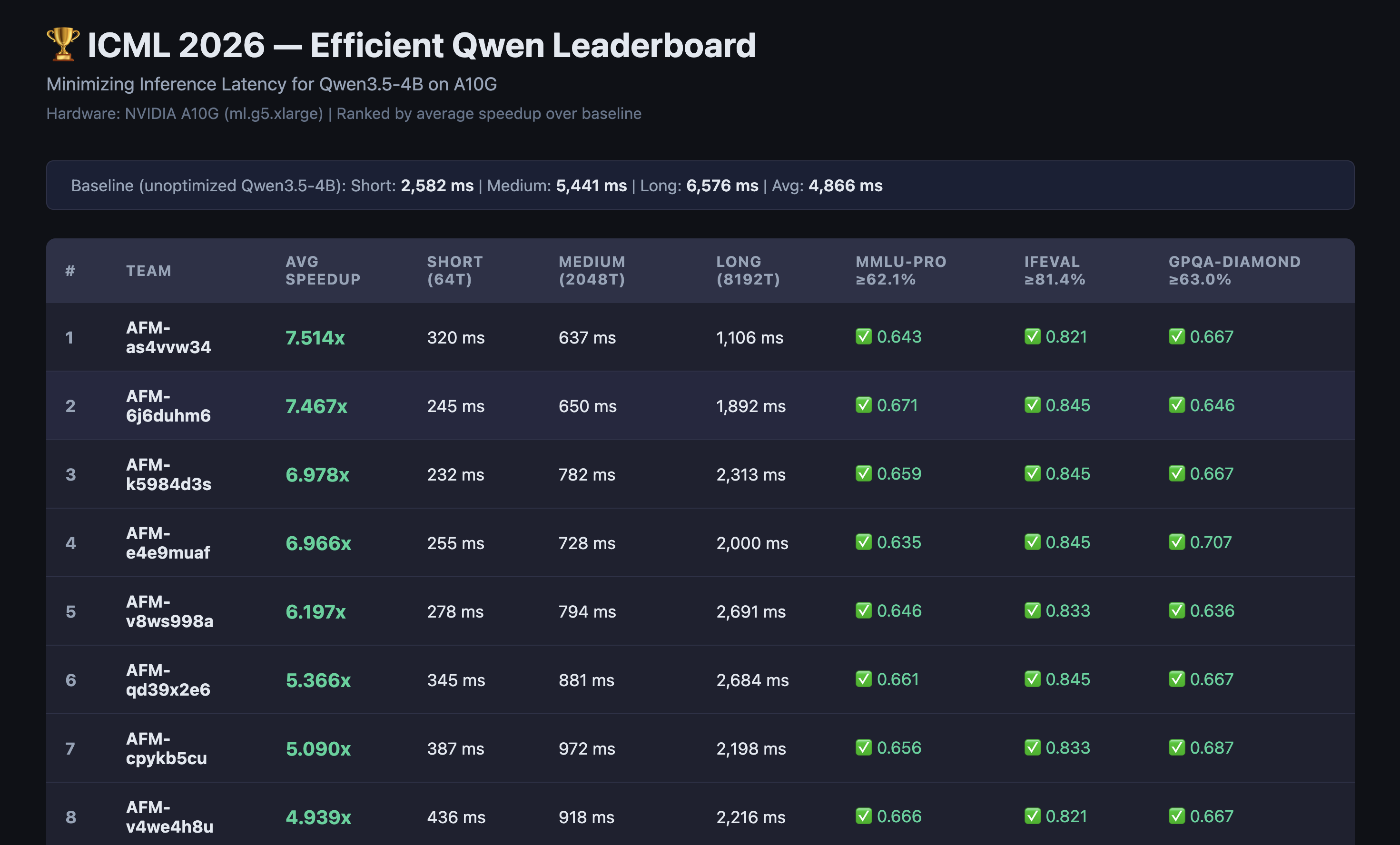
The official leaderboard was much faster than my local best. That was expected, and honestly it made the challenge more interesting. The top teams were clearly operating at a different systems level, especially on kernel work and deeper serving stack changes.
What This Taught Me
This concluded my two week sprint of taking part in my first AI conference workshop challenge, the Efficient Qwen competition at AdaptFM, ICML 2026.
Since I had basically no real experience in writing kernels, quantization, pruning, or model distillation, this was the perfect sprint to come across so many model inference optimization techniques. The AdaptFM workshop question is very interesting to me: how can foundation model inference adapt to a resource budget, whether that budget is memory, compute, latency, energy, or cost, while still maximizing output quality?
I also came out of this with a stronger belief that AI research loops can be partially automated when the evaluator is tight. My Parameter Golf post was the first time I saw this shape. Efficient Qwen made it more concrete because the loop had a real model, a single GPU target, quality gates, and many systems knobs. It felt like watching an AI model help me reason about making another AI model faster.
The code for this effort is private for now because the project is messy and very experiment shaped. I might clean it up later, but for now the main artifact is the learning and this writeup.
Links
Challenge And Context
My Related Posts
Why I Took This Up
I decided to take part in the Efficient Qwen competition at AdaptFM, happening at ICML 2026. The full challenge name was Efficient Qwen: Minimizing Inference Latency for Qwen3.5-4B on A10G.
This was my first ever solo AI conference shared task effort, so I was not entering it as someone who already knew how to write CUDA kernels, quantize models properly, prune transformer layers, or do serious model distillation. I entered it because the problem statement felt very direct:
I started working around June 1. The final competition deadline was June 17, 2026 AoE, which was June 18, 2026 at 5:29 PM IST. So in practice this became a very short two week sprint where I had to set up infra, understand the rules, run latency experiments, keep notes, and decide which ideas were actually worth chasing.
This felt connected to my earlier Parameter Golf experiment, but the axis changed. Parameter Golf was about making a tiny model fit inside a strict artifact size. Efficient Qwen was about taking a capable existing model and making inference faster under a real hardware budget.
The Rules
The nice thing about this challenge was that the optimization space was wide open, but the quality gates made it honest. You could use quantization, pruning, distillation from Qwen3.5-4B, architecture changes, custom CUDA or Triton kernels, custom inference engines, KV cache optimization, operator fusion, speculative decoding,
torch.compile, Flash Attention variants, and memory offload.But you could not use cached answers, benchmark detection, routing logic, eval data training, closed software, or a model stack that exceeded the original Qwen3.5-4B parameter count. Also, a single model stack had to serve the endpoints. That constraint matters a lot because otherwise it becomes easy to make one path fast for latency and another path smart for quality.
The quality gates were MMLU-Pro at least
62.1%, IFEval at least81.4%, and GPQA-Diamond at least63.0%. The latency score used three buckets: short prompts with64input tokens, medium prompts with2048input tokens, and long prompts with8192input tokens. The official baseline average was4866 ms, and the score was average speedup over that baseline.This is what I liked about it. It was not just "make it fast." It was "make it fast on one A10G, keep the same model family, respect the API contract, pass quality, and do not cheat."
Setting Up The Experiment Loop
I did not have a local GPU, so the first part was just getting a workflow running on remote GPU infra. I used Modal because I already had some experience with it from earlier experiments, and because it made short iteration loops less painful than keeping a machine alive manually.
The local project became a small experiment lab. I had a Modal volume with original weights, quantized weights, pruned checkpoints, KD checkpoints, and a bunch of failed or half useful variants sitting side by side.
The first useful thing was not even a model trick. It was making the experiment tracker good enough that I could trust it. Every run needed a name, exact latency numbers, what changed, what stayed fixed, and whether the result was valid or risky. Without that, 20 experiments later everything becomes mush.
My loop became:
This is the part where I started thinking more seriously about autoresearch. The problem had a clean evaluator, a search space, a leaderboard style metric, and enough knobs that manual iteration felt slow. It reminded me of the NanoGPT speedrun style of work, where the fixed benchmark makes every small improvement visible.
The First 57 Experiments
In the first eight days I had already reached 57 total experiments. Not all of them were meaningful. Some failed during startup. Some served but were slower. Some looked smart in my head and dumb on the graph. But this was the whole point.
The early improvements came from stacking boring but powerful things. vLLM runtime tuning helped. N-gram speculative decoding helped a lot. GPTQ INT4 Marlin changed the weight path. Prefix caching was a very big jump. Then the later improvements became more specific: exact CUDA graph capture sizes,
torch.compile, better compile ranges, and Qwen3.5 specific cache settings.I also tried directions that did not work well. SGLang was interesting, but I kept hitting startup and kernel path issues. llama.cpp and GGUF were worth checking, but not the main path. AutoRound and AWQ were useful to understand, but the GPTQ INT4 Marlin stack was the one that kept surviving the loop.
One thing I learned here is that model latency optimization is a very humbling kind of work. A knob can sound obviously better and still regress because it changes graph capture, kernel dispatch, cache behavior, or just one ugly interaction inside the serving engine.
The Best Local Stack I Found
The best non risky local stack in my experiment tracker was
exp111, at4.342xaverage speedup on my Modal A10 latency loop. It reached around960 msshort,1051 msmedium, and1274 mslong.The stack was not one magic trick. It was a composition:
0.21.0torch.compileThis small config chain is basically the shape of the champion local setup:
And the serving entrypoint stayed simple:
That simplicity is a little misleading though.
_exp111_env()carried a whole ancestry of earlier wins: prefix caching, speculative decoding, graph capture sizes, compile ranges, cache mode alignment, and block size tuning. The point was not that one line made the model fast. The point was that the tracker let me accumulate small wins without losing the exact recipe.The waterfall plot made that clearer than the raw table.
The Distillation Attempt
I also ran a knowledge distillation experiment because the rules allowed distillation as long as the student was initialized from Qwen3.5-4B. That caveat is important. A separate tiny model could not just be used as a draft or student if it did not come from the original 4B weights.
My distillation idea was to repair a previously pruned student. Qwen3.5-4B has
32text layers. I had a BI-pruned20layer student, where the pruning removed complete groups while trying to preserve the original attention block structure. The KD run did not remove more layers. It tried to teach the damaged 20 layer student to imitate the frozen 32 layer teacher again.The training setup matched the student against the teacher's top
128token probabilities, while also keeping normal next token prediction. I used FineWeb Edu streaming data and filtered out contamination terms likemmlu,gpqa, andifevalbecause the quality eval benchmarks were part of the competition rules.The core loss shape looked like this:
This did not become my winning path, but it was one of the most useful learning parts of the sprint. Distillation stopped being just a word from papers and became a concrete thing I could run, inspect, spend money on, and mess up.
Watching The Frontier Move
By the end, I had conducted
142major experiments, fromexp01throughexp143, excluding onlyexp141which was never run. This does not even count the letter variant sub-parts like17Aand17B, or18Athrough18E. The structured experiment file had152rows in total, with most runs sitting around vLLM, GPTQ, prefix caching, speculative decoding, compile settings, and derivative stacks from earlier winners. A lot of dots did not matter. The frontier did.The thing I liked most was seeing how the frontier moved in jumps.
exp02made raw vLLM much faster through n-gram speculation.exp12got a big jump from GPTQ plus prefix cache plus n-gram32.exp21,exp29,exp43,exp51,exp74, and finallyexp111each moved the best known stack a little further.My final max clean speedup over the official baseline was
4.342xwithexp111. That stack came in at around960 msshort,1051 msmedium, and1274 mslong, compared with the official baseline average of4866 ms. There were raw completion cap experiments, likeexp40, that touched4.958x, but I kept those separate because they were explicitly risky and not clean submission candidates.I also had a few results that looked fast but were not clean for submission. This is another good lesson from challenges. A number is not enough. You have to ask: did it respect the rules, did it use the same stack, did it preserve quality, and would it survive the official evaluator?
The official leaderboard was much faster than my local best. That was expected, and honestly it made the challenge more interesting. The top teams were clearly operating at a different systems level, especially on kernel work and deeper serving stack changes.
What This Taught Me
This concluded my two week sprint of taking part in my first AI conference workshop challenge, the Efficient Qwen competition at AdaptFM, ICML 2026.
Since I had basically no real experience in writing kernels, quantization, pruning, or model distillation, this was the perfect sprint to come across so many model inference optimization techniques. The AdaptFM workshop question is very interesting to me: how can foundation model inference adapt to a resource budget, whether that budget is memory, compute, latency, energy, or cost, while still maximizing output quality?
I also came out of this with a stronger belief that AI research loops can be partially automated when the evaluator is tight. My Parameter Golf post was the first time I saw this shape. Efficient Qwen made it more concrete because the loop had a real model, a single GPU target, quality gates, and many systems knobs. It felt like watching an AI model help me reason about making another AI model faster.
The code for this effort is private for now because the project is messy and very experiment shaped. I might clean it up later, but for now the main artifact is the learning and this writeup.
Links
Challenge And Context
Related Reading
My Related Posts